基于RAG构建法律条文助手,llamaindex框架,自定义数据划分方式,分为基础搭建,重排序优化,性能优化几个步骤。
本文涉及的数据和代码在: RAG实现法律助手,包括代码和数据资源-CSDN下载
用到的模型有:
对话模型: Qwen1.5-1.8B-Chat
词嵌入模型: text2vec-base-chinese
重排序模型: text2vec-base-chinese-sentence
一. RAG基础实现与优化
1.1 核心原理
检索增强生成(Retrieval-Augmented Generation) 通过结合检索系统与大语言模型(LLM)实现精准回答:
- 用户提问: 接受自然语言问题
- 向量检索: 从法律条文库中检索相关条框
- 结果精炼: 将检索结果输入LLM生成最终回答
用户提问向量检索Top-k条款生成结构化回答
1.2 基础实现代码
和上一章代码类似, 区别是加载大语言模型,提供回答功能,具体代码在test01.py中,其中用到的知识库是上一章构建的知识库。
1 | # 初始化基础组件 |
输出示例:
问题1:劳动合同试用期最长可以约定多久? 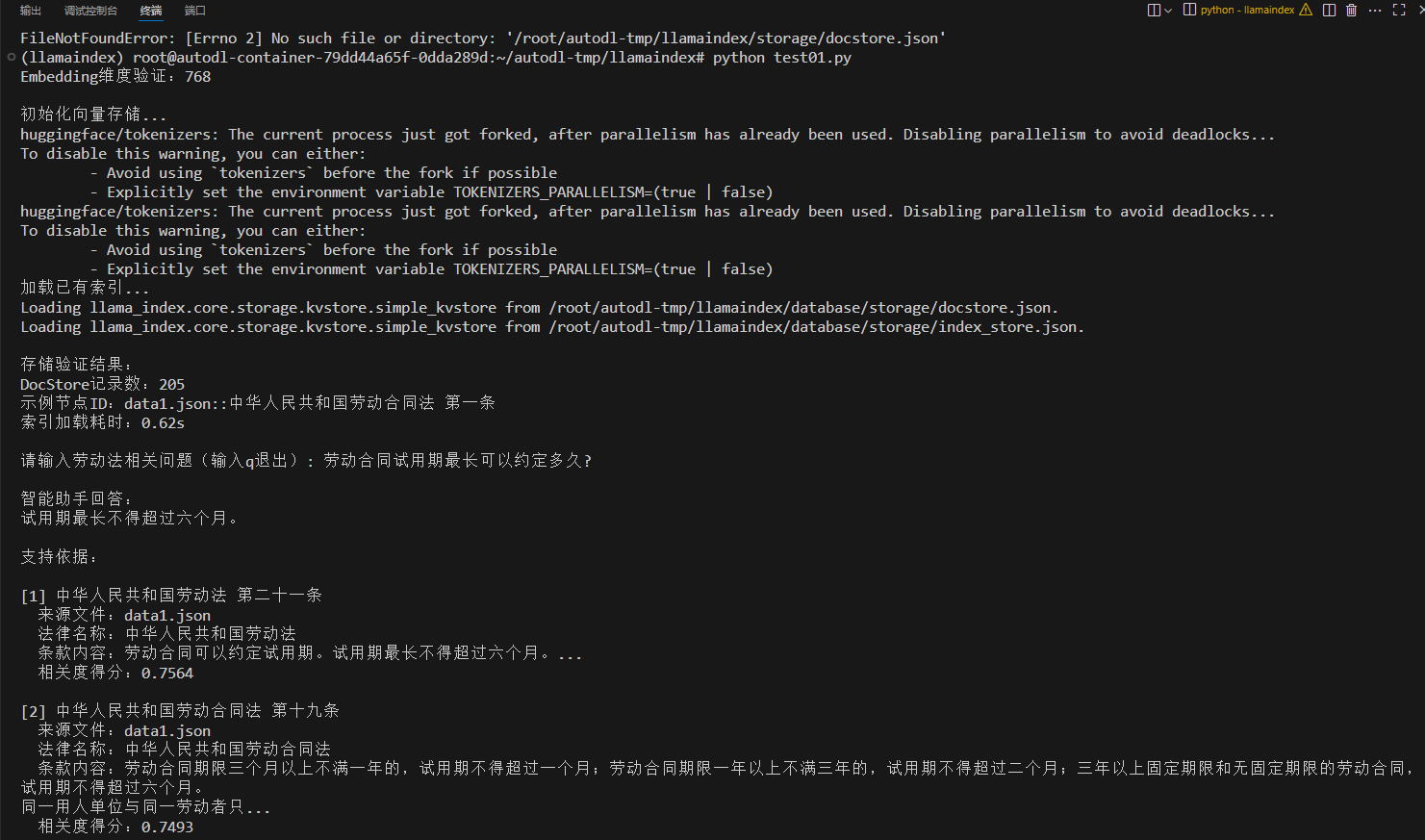
可以看出,召回的法律条款都是和劳动还有时间相关的,召回的相似度最大的中华人民共和国劳动法第二十一条中直接指出试用期最长不超过六个月,所以大模型根据条款给出了正确回答,但也召回了一些不相关的条文。
问题2:加班工资应该如何计算?

给出了一个计算公式,也召回了一些正确信息,但模型回答不完整,这个可能是使用huggingface推理引擎的原因。
问题4:劳动者可以解除合同的情形有哪些?(召回错误信息)

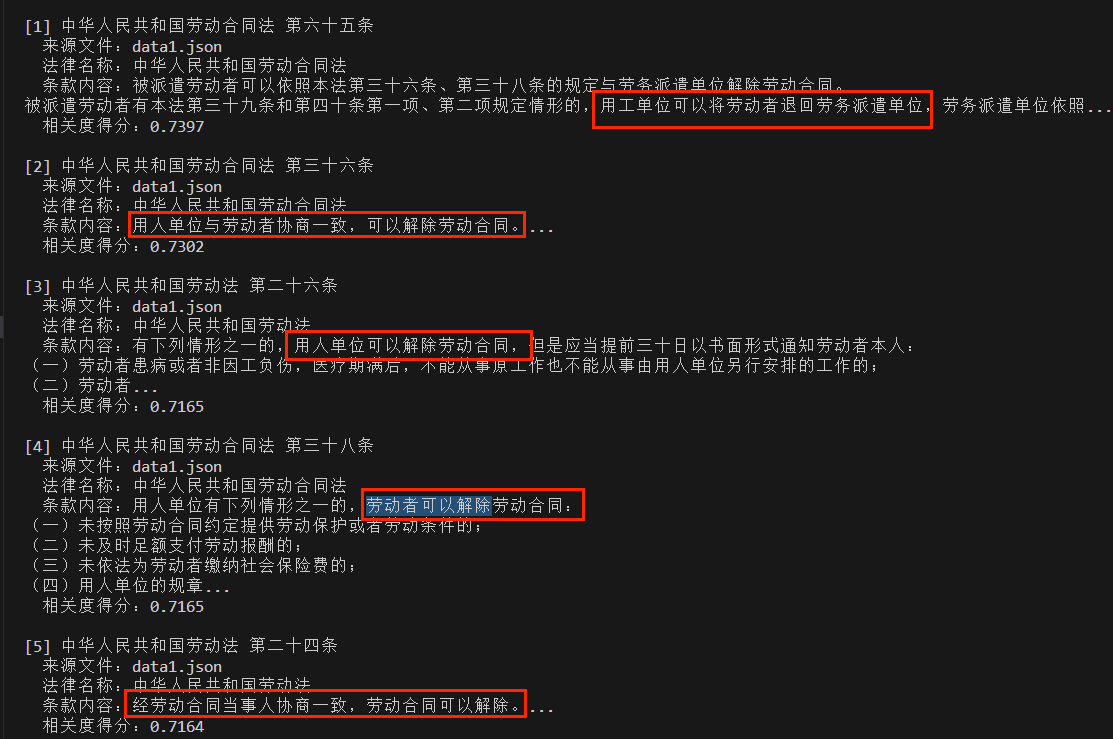
模型因为理解不了劳动者主动解除劳动合同和用人单位解除劳动合同,召回了一些错误信息,即模型不能理解主被动关系。
问题5:哪种情况下,用人单位可以解除劳动合同?
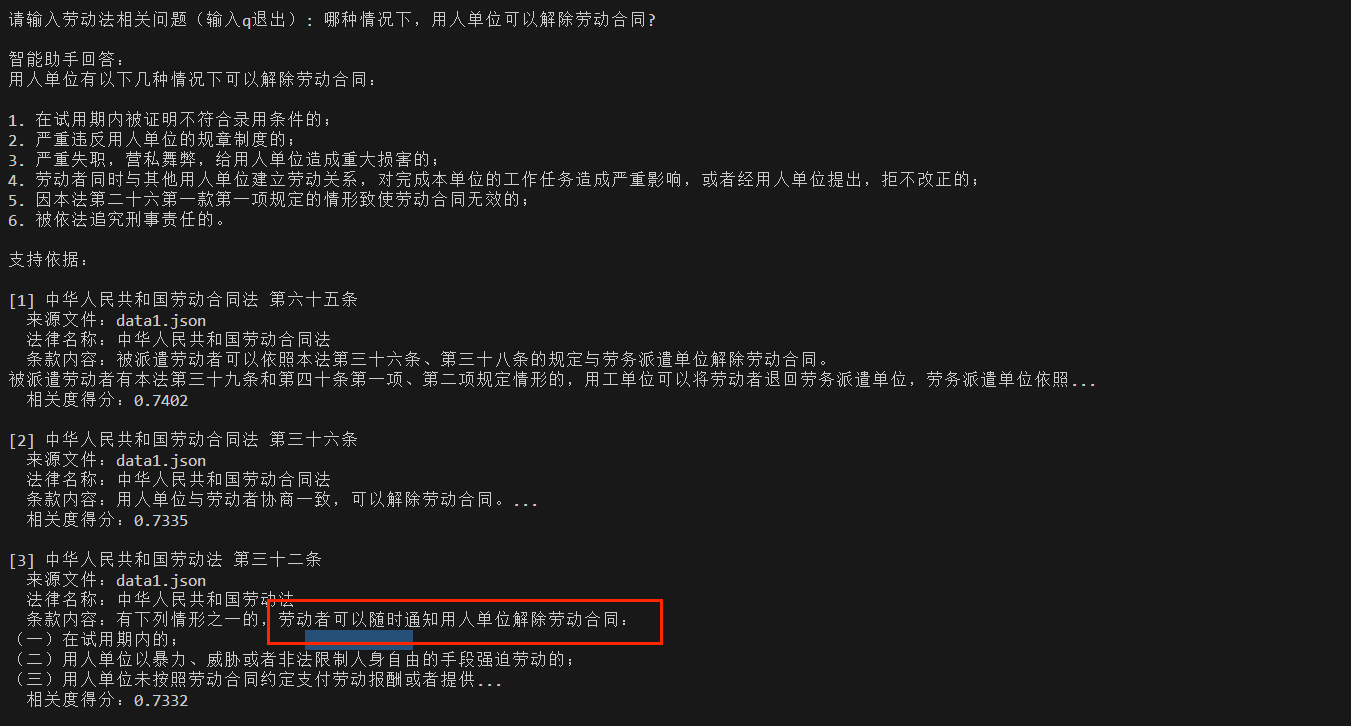
同样的,模型无法理解主被动关系,召回了一些错误信息。
出现错误样例的原因:
- LLM理解问题不行: 加大模型参数, 微调。
- 召回不行: 重排
优点: 召回的数据是和答案有相关性的,
缺点: 加入了一些相关性不高的内容。没有限制, 就算和知识库完全无关,还是有回答,并且会返回检索到的内容,尽管它们和问题无关。
为什么问题和知识不相关, 但相似度还是很高:都是中文,语义都是正确的,(0.7-0.8)
回复不完整: 模型有问题,提示词有问题,长度限制。
1.3 优化策略对比
| 优化维度 | 优化前 | 优化后 |
|---|---|---|
| 检索范围 | 固定Top3 | 初筛Top10+精排Top3 |
| 排序方式 | 余弦相似度 | 语义重排序模型 |
| 提示词设计 | 简单模板 | 强化约束的多条件模板 |
二. 重排序优化
在上面的RAG中,我们每次都召回条知识,不管相似度多低,都返回相似度最高的10条知识,会导致幻觉,即即使问了不相关问题,仍然会召回知识并回复,比如: 义务教育一共有几年?

还是召回了10条知识,尽管他们和问题不相关,这会影响模型回答,这个问题是因为问题太简单,在模型的预训练预料中,模型根据自身能力解决了。为了提高召回精度,我们加入重排序。
2.1 重排序
两阶段检索机制提高召回精度:
1. 初筛阶段: 使用向量检索获取候选集(Top10)。
2. 精排阶段: 通过专用重排序模型计算语义相关性。根据重排序结果取得分超过阈值的知识。
2.2 关键词+重排序过滤
在日常使用中,我们一般希望模型只回答领域相关问题,但目前如果提问无关问题(比如,你好,你叫什么名字)模型仍然会根据自己的知识回答,在实际应用中,可以对重排序结果进行处理,低于阈值则不采用该知识,当没有召回任何知识时,直接返回”无法回答”而不调用大模型回答。
优化后的代码在test03.py中, 主要改变是新增过滤函数, 分为关键词过滤和重排序过滤, 如果没有关键词或检索不到知识,则直接回复而不调用大模型。
关键词过滤适合在提出问题的人具备一定的领域知识,提出问题比较规范的情况下,这里考虑到提问者可能不是法律工作者,所以直接用重排序模型。
1 | from llama_index.core.postprocessor import SentenceTransformerRerank # 新增重排序组件 |
2.2 效果测试
女职工产假最新规定是多少天?
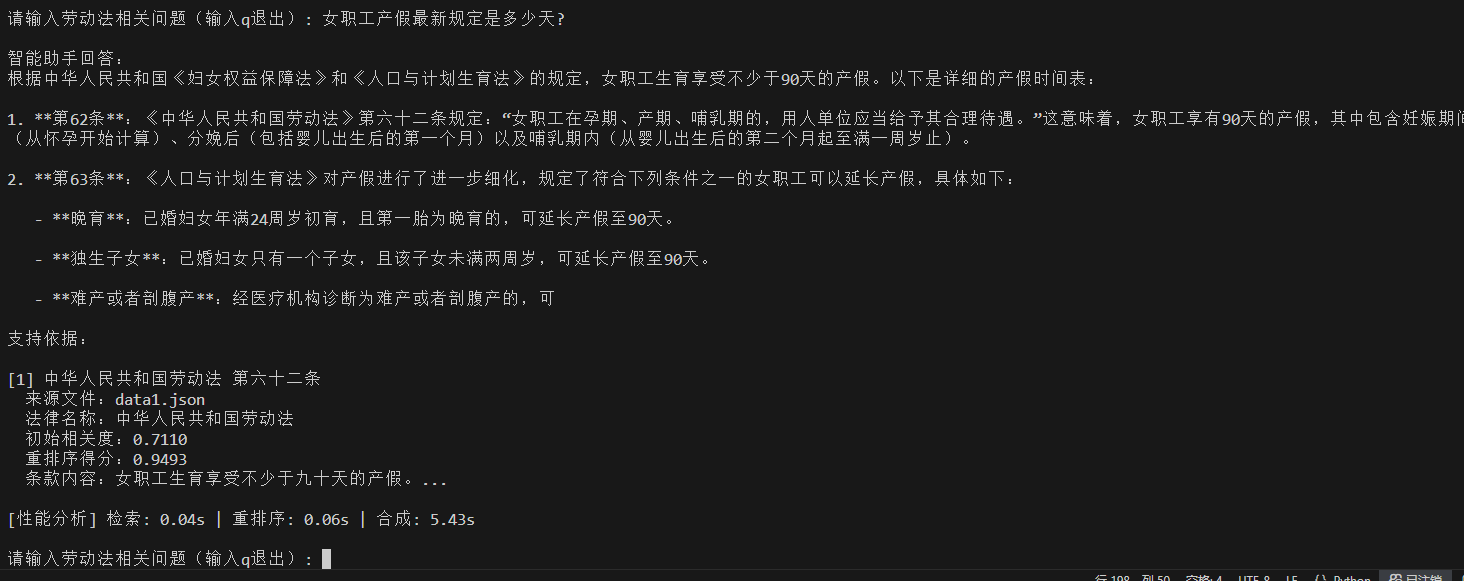
模型根据重排序结果过滤,召回更准确的信息。只召回了一条信息,其他不相关信息没有召回。

如果提问了劳动法无关的问题,也能返回预定回答,避免大模型幻觉造成干扰。
三. 性能提升
目前的大模型都是用huggingface引擎的,模型推理速度慢,大模型可以用vllm等推理框架部署,llamaIndex修改可以参考Openai like - LlamaIndex
主要将模型加载替换为openai-API格式
1 | from llama_index.llms.openai_like import OpenAILike |
同样的,嵌入模型和rerank模型也可以用vllm部署,但vllm部署的时候一个模型都要几乎一张卡,所以如果用vllm部署,尽量一个模型部署到一张卡上。如果预算不足,可以用ollama,真正应用上不要用huggingface引擎。
部署可以参考 大模型应用系列(六) ollama,vllm,LMDeploy 部署大模型 | 乌漆嘛黑 这里没有多张卡,所以只用vllm部署了chat模型,其他还是用huggingface引擎,在vllm指令中指定--gpu-memory-utilization 0.5 指定GPU占用率为50%,留出部分显存给其他两个模型。
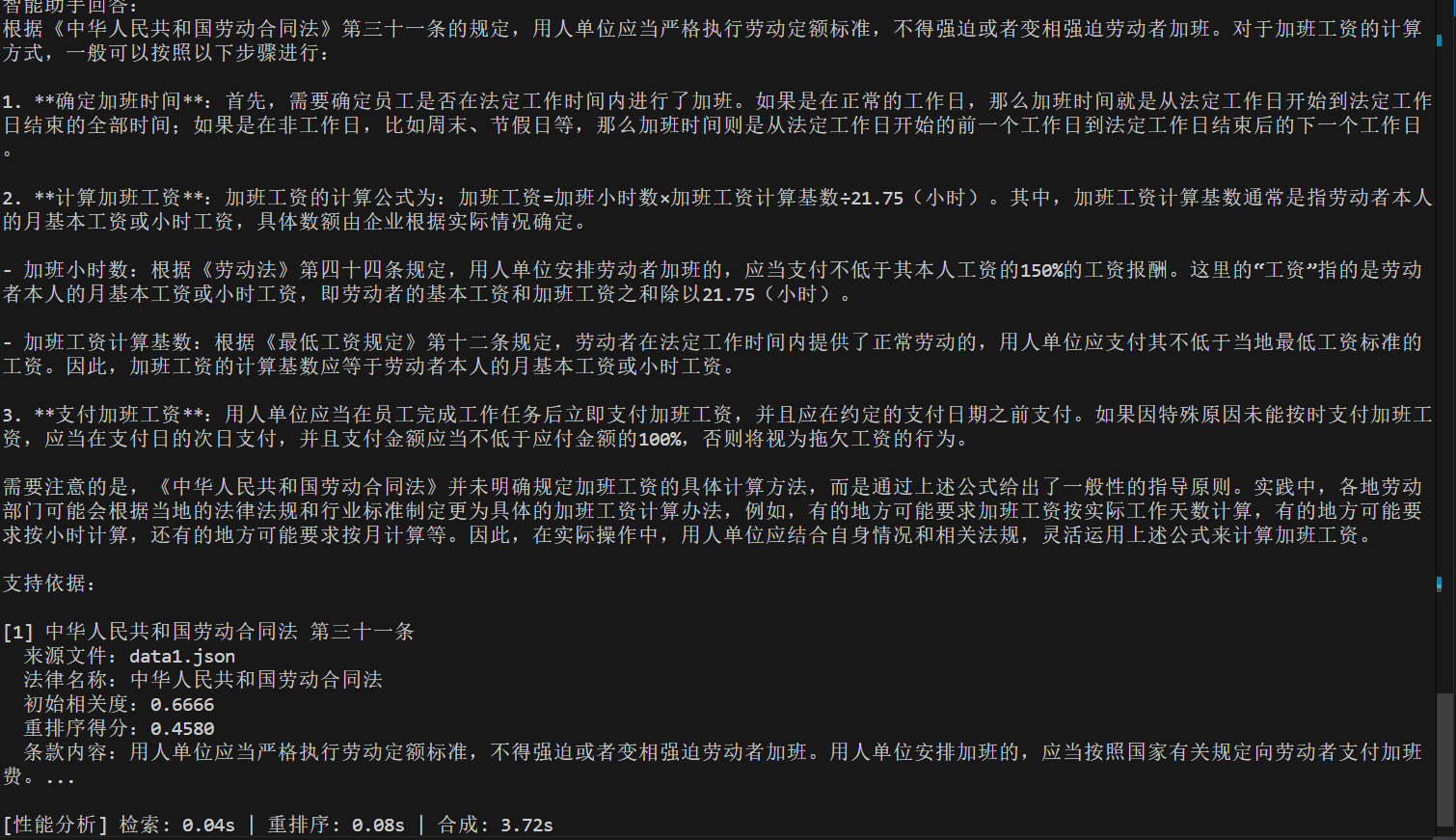
测试问题:加班工资应该如何计算?
这个问题在1中使用huggingface引擎结果不完整,这里用vllm得到完整结果,所以在应用中尽量使用vllm部署。
四. 补充
4.1 重排序原理
4.1.1 初始检索器
评分原理: 基于Bert等双编码器模型生成文本嵌入,计算词向量的余弦相似度。
特点: 快速计算,分数范围通常为0~1
4.1.2 重排序
评分原理: 使用BGE-reranker等交叉熵编码器计算query-doc
特点: 计算代价高,分数范围可能为任意实数(需sigmoid处理为(0~1)
