介绍RAG中常用的文档切分方式,如何提升召回率,以及简要介绍重排序。
本文用到的文档可以在【免费】RAG文档资料,用于用llamaindex构建RAG的测试程序资源-CSDN下载 下载。
一. 文档解析 参考: SimpleDirectoryReader 的并行处理 - LlamaIndex 框架
1.1 什么是文档解析? 文档解析实际上就是读取文件,就像把不同包装的食品拆开处理:
PDF文件:罐头食品(需要用专用工具打开)
Word文档:盒装饼干(容易拆但可能有碎屑)
扫描件/图片:真空包装(需要剪刀才能打开)
1.2 基础解析 1.本地文档
常见的有pdf, txt, md, word,都可以用llamaindex自带的simple_direct_reader 读取。示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from llama_index.core import SimpleDirectoryReader reader = SimpleDirectoryReader( input_files=["/root/autodl-tmp/day19/data/report_with_table.pdf" ] ) docs = reader.load_data() print (docs)
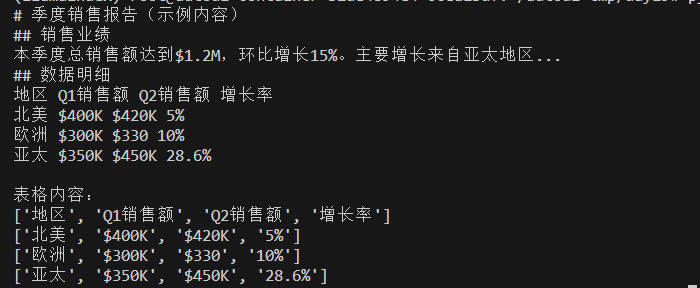
每个文档读取完就是一个node, 但它的解析功能比较简单,比如对于表格信息,并不能保持它的格式,如下:
读取后表格变成文本形式了,同时可以看到,llamaindex解析文档后默认情况下把整个文档作为一个node,同时会保存文件名,路径,类型,大小等元数据。
2.读取本地html文件
llamaindex同样自带html的解析包,对于,网页,可以使用如下方式解析
安装解析包:
1 2 pip install llama-index-readers-file pip install html2text
使用SimpleWebPageReader
1 2 3 4 5 6 7 8 9 10 11 from llama_index.readers.file import HTMLTagReaderreader = HTMLTagReader(tag="section" , ignore_no_id=True ) docs = reader.load_data( "/root/autodl-tmp/day19/data/document.html" ) for doc in docs: print (doc.metadata) print (docs)
但它只能加载本地缓存的html文件。如果要很好地爬取数据,还是用传统的爬虫(beautiful soup)效果比较好。
3.读取在线网页
可以使用SimpleWebPageReader读取在线网页:安装
1 pip install llama-index llama-index-readers-web
加载网页
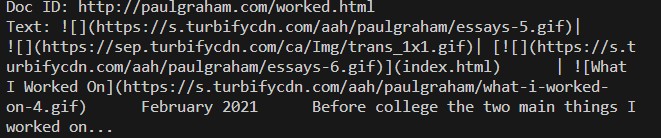
1 2 3 4 5 from llama_index.readers.web import SimpleWebPageReaderdocuments = SimpleWebPageReader(html_to_text=True ).load_data( ["http://paulgraham.com/worked.html" ] ) print (documents[0 ])
结果如下:但这个不会进入网页中的超链接爬取更多数据:
也可以用Spider,Spider是最快的爬虫,可以将任何网站转换为html, markdown, 元数据或文本,同时支持使用AI进行自定义操作来爬取
Spider 允许您使用高性能代理来防止检测,缓存 AI 操作,提供爬取状态的 webhook,支持计划爬取等。
先决条件: 您需要有一个 Spider API 密钥才能使用此加载器。可以在 spider.cloud 获取。但这个收费,我没有尝试。
1 2 3 4 5 6 7 8 import SpiderWebReader spider_reader = SpiderWebReader( api_key="YOUR_API_KEY" , mode="scrape" , ) documents = spider_reader.load_data(url="https://spider.cloud" ) print (documents)
总的来说,llamaindex提供的解析工具不能很好地满足要求,所以一般用更好的第三方工具。对于网页,最好的还是网页爬虫。
1.3 高级解析 初级解析的优点是方便使用,缺点是功能简单,像上面的表格数据就无法很好解析。很多第三方包提供了很好的解析工具,比如为了更好地解析表格,可以使用pdfplumber, 示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pdfplumberwith pdfplumber.open ("报告.pdf" ) as pdf: text = "" for page in pdf.pages: text += page.extract_text() print (text[:200 ]) for page in pdf.pages: tables = page.extract_tables() for table in tables: print ("\n表格内容:" ) for row in table: print (row)
如果文件中有图片,要提取图片中的文字,则可以用OCR。魔塔社区直接搜OCR就有开源的OCR模型。
如下, 提取后数据保持表格形式。
1.4 总结 如果文档简单(只有文字),则可以用llamaindex自带的解析器,如果文档复杂(涉及表格,图片,html等),则用第三方工具。
二. 文本切分 2.1 为什么需要切分 使用dataconnector加载数据时,会默认一个文档就是一个document,也就是一个节点,在检索的时候就会检索到整个文档,这样不仅prompt太长,还可能很多噪音。
2.2 切分三要素
要素
说明
推荐值
块大小
每段文字的长度
200-500字
块重叠
相邻块重复内容,用于表示上下文
10%-20%
切分依据
按句子/段落/语义切分
语义分割最优
2.3 分块策略对比
策略类型
优点
缺点
适用场景
固定大小
实现简单
可能切断完整语义
古诗,对联等句式整齐的
按段落分割
保持逻辑完整性
段落长度差异大
文学小说·
语义分割
确保内容完整性
计算资源消耗大
专业领域文档
正则匹配
效果好
需要写正则表达式
基本都可以
2.4 分块常见问题 2.4.1 如何确定最佳块大小 测试不同尺寸查看检索效果
1 2 3 4 5 sizes = [128 , 256 , 512 ] for size in sizes: rest_call = evaluate_chunk_size(size) print (f"块大小{size} 召回率{rest_recall:.2 f%} " )
2.4.2 分块是否重叠越多越好 适当重叠(10%-20%)可以防止信息断裂,但过多会造成冗余。
2.5 切分示例: 固定分块vs语句切分vs语义切分 固定分块: 到达chunk_size马上切分
语句切分: 尽量让句子保持完整,如果开始下个句子后会超出chunk_size,则从当前句子切分
语义切分: 利用大模型的语义理解能力,将表达完整的语句作为一个分块。
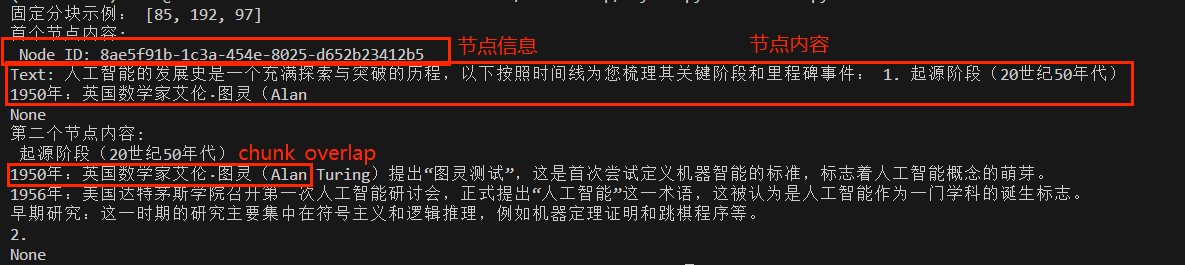
2.5.1 固定分块 1 2 3 4 5 6 7 8 9 10 11 12 13 from llama_index.core import SimpleDirectoryReaderdocuments = SimpleDirectoryReader(input_files=["/home/cw/projects/demo_20/data/ai.txt" ]).load_data() from llama_index.core.node_parser import TokenTextSplitterfixed_splitter = TokenTextSplitter(chunk_size=256 , chunk_overlap=20 ) fixed_nodes = fixed_splitter.get_nodes_from_documents(documents) print ("固定分块示例:" , [len (n.text) for n in fixed_nodes[:3 ]]) print (print ("首个节点内容:\n" , fixed_nodes[0 ].text))print (print ("第二个节点内容:\n" , fixed_nodes[1 ].text))
结果如下:
2.5.2 语句切分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from llama_index.core.node_parser import SentenceSplitterfrom llama_index.core import SimpleDirectoryReaderdocuments = SimpleDirectoryReader(input_files=["/root/autodl-tmp/day19/data/ai.txt" ]).load_data() splitter = SentenceSplitter(chunk_size=128 , chunk_overlap=50 ) nodes = splitter.get_nodes_from_documents(documents) print (f"生成节点数: {len (nodes)} " )print ("首个节点内容:\n" , nodes[0 ].text)print ("第二个节点内容:\n" , nodes[1 ].text)
结果如下: 根据语义第一个节点中”1. 起源阶段…”部分文字被划分到第二个节点, 因为加上这部分就会超了,句子说不完整。
2.5.3 语义切分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from llama_index.core import SimpleDirectoryReaderfrom llama_index.embeddings.huggingface import HuggingFaceEmbeddingfrom llama_index.core.node_parser import SemanticSplitterNodeParserimport osdocuments = SimpleDirectoryReader(input_files=["/home/cw/projects/demo_20/data/test.txt" ]).load_data() embed_model = HuggingFaceEmbedding( model_name="/home/cw/llms/embedding_model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" ) semantic_parser = SemanticSplitterNodeParser( buffer_size=1 , breakpoint_percentile_threshold=90 , embed_model=embed_model ) semantic_nodes = semantic_parser.get_nodes_from_documents(documents) print (f"语义分割节点数: {len (semantic_nodes)} " )for i, node in enumerate (semantic_nodes[:2 ]): print (f"\n节点{i+1 } :\n{node.text} " ) print ("-" *50 )
对比三种分块方法,第三种最好,因为它借助了大模型的语义理解能力,不会造成句子语义不完整:
但第三种同样存在问题,比如在分割法律条款时,它将所有的法律条款视为一个分块,而我们在实际中一般需要它按章节以及条目进行分块。
实际上文档切分并没有固定的处理方式,需要根据知识文档的数据格式选择切分方式,所以还需要结合正则匹配,甚至人工划分。
三. 召回率提升方案 3.1 什么是召回率 召回率涉及的是检索阶段。检索逻辑太粗会导致一些信息没有被召回,召回率低。检索逻辑太细会导致一些冗余信息被召回,导致准确率低。
首先得把召回率提上来,后面再把准确率提高,比如有8个node个查询有关,如果一开始只准确召回4个(召回率低,准确率高),那后面再怎么处理都没用了;如果一卡是召回12个,里面有8个正确4个错误(召回率高,准确率低),那么召回后可以通过重排提高准确率。
3.2 提升召回率的三大策略: 3.2.1 查询扩展: 给问题加修饰词
原始问题: 如何做番茄炒蛋
扩展后: 家常番茄炒蛋做法步骤,厨房新手教程,简单易学。
3.2.2 混合检索: 结合两种搜索方式 1 2 3 graph LR A[用户问题]-->B[关键词搜索]-->C[初步结果]-->D[合并去重] A-->E[语义搜索]-->C
用户问题关键词搜索语义搜索初步结果合并去重。
但是混合检索也有弊端: 响应慢。关键词搜索的前提是用户规范提问,能问到点子上(关键词)
3.2.3 向量优化 微调大模型型,如果数据集中含有专有名词,大模型不能理解,则需要微调。再RAG中成为“向量优化”。
微调前: Transformer 理解为 “变形金刚”
微调后: Transformer 理解为”深度学习模型”。
3.2.4 基础检索vs混合检索
下面用一个完整的RAG代码展示向量检索和关键词检索的效果对比:代码流程未: 加载本地Embedding模型和LLM模型—>加载并解析数据—>检索—>查询,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 from llama_index.embeddings.huggingface import HuggingFaceEmbeddingfrom llama_index.core import Settings, VectorStoreIndexfrom llama_index.llms.huggingface import HuggingFaceLLMfrom llama_index.core.schema import TextNodeimport jsonimport torchdef setup_local_models (): embed_model = HuggingFaceEmbedding( model_name="/home/cw/llms/embedding_model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" , device="cuda" if torch.cuda.is_available() else "cpu" ) llm = HuggingFaceLLM( model_name="/home/cw/llms/Qwen/Qwen1.5-1.8B-Chat" , tokenizer_name="/home/cw/llms/Qwen/Qwen1.5-1.8B-Chat" , model_kwargs={"trust_remote_code" : True }, tokenizer_kwargs={"trust_remote_code" : True }, device_map="auto" , generate_kwargs={"temperature" : 0.3 , "do_sample" : True } ) Settings.embed_model = embed_model Settings.llm = llm Settings.chunk_size = 512 def load_data (file_path ): with open (file_path, 'r' , encoding='utf-8' ) as f: data = json.load(f) nodes = [] for item in data: if isinstance (item, dict ): if 'query' in item and 'positive_passages' in item: text = f"查询: {item['query' ]} \n相关文档: {item['positive_passages' ][0 ]['text' ]} " elif 'question' in item and 'answer' in item: text = f"问题: {item['question' ]} \n答案: {item['answer' ]} " else : continue elif isinstance (item, str ): text = item else : continue node = TextNode(text=text) nodes.append(node) return nodes setup_local_models() data_path = "/home/cw/projects/demo_19/data/qa_pairs.json" nodes = load_data(data_path) query = "如何预防机器学习模型过拟合?" vector_index = VectorStoreIndex(nodes) vector_retriever = vector_index.as_retriever(similarity_top_k=3 ) print ("向量检索结果:" , [node.text[:50 ] + "..." for node in vector_retriever.retrieve(query)])from llama_index.core import KeywordTableIndexkeyword_index = KeywordTableIndex(nodes) keyword_retriever = keyword_index.as_retriever(similarity_top_k=3 ) print ("关键词检索结果:" , [node.text[:50 ] + "..." for node in keyword_retriever.retrieve(query)])query_engine = keyword_index.as_query_engine() response = query_engine.query(query) print ("LLM生成回答:" , response)
使用的数据如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "query" : "如何预防机器学习模型过拟合?" , "positive_passages" : [ "正则化方法通过添加L1/L2惩罚项控制模型复杂度..." , "交叉验证将数据划分为训练集和验证集..." , "早停法(Early Stopping)监控验证集损失..." ] , "negative_passages" : [ "GPU加速训练的技术方案..." , "数据标注的质量控制方法..." , "卷积神经网络结构解析..." ] }
3.3 效果验证方法
准备测试问题集(至少50个典型问题)。
记录基础方案召回率。
应用优化策略后再次测试。
对比提升幅度。
四. 检索结果重排序 4.1 为什么要重排序 在召回期间,我们是尽量提升召回率,所以和问题沾边的都召回了,导致召回的数据中很多冗余的,要经过重排序把这些冗余的排除。重排序的目的是提高模型响应的精度。排序需要用到重排序模型。
4.2 常见排序模型对比
模型名称
速度
精度
硬件要求
使用场景
BM25
块
中
低
关键词匹配
Cross-Encoder
慢
高
高
小规模精准排序
ColBERT
中
高
中
平衡速度与精度
重排序的效果要在实际项目中展示,在后面项目中再详细说明。