简要介绍Embedding Models以及如何根据数据集选择合适的嵌入模型。
一. Embedding Models 嵌入模型原理及选择 文档向量化后构成知识库,但如果文档不变化,并不需要每次都读文档并且进行向量化。真正上应该是将向量化后的文档存储到数据库,这样下次访问就不用重复读取和向量化。
另外,文本本身也有差异性,不同类别的文本应该选择不同的Embedding model进行向量化,但这一步的效果影响不大,如果其他优化都用了之后效果还不好,再考虑嵌入模型的影响。
1.1 嵌入模型的本质 嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间中距离更近。例如,“忘记密码”和“账号锁定”会被编码为相近的向量,从而支持语义检索而非仅关键词匹配。
度量向量的相似度一般用余弦相似度,欧氏距离,内积。但一般用余弦相似度,因为它是归一化的,值在[-1,1]之间,其他没有归一化,无法判断是否接近。
1.2 核心作用 语义编码:将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。
相似度计算:通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。
信息降维:压缩复杂数据为低维稠密向量,提升存储与计算效率。
1.3 关键技术原理 上下文依赖:现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。(一个词根据上下文可以有不同的词向量)
训练方法:对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。
二. 主流模型分类与选型 2.1 考虑因素 Embedding模型将文本转换为向量,捕捉语义信息,使计算机能够理解和比较内容的“意义”。大的方向上嵌入模型可以分为中文和应为,细分上选型时可以考虑的因素有:
因素
说明
任务性质
匹配任务需求(问答,搜索,聚类等)
领域特性
通用vs专业领域(医学,法律等)
多语言支持
需处理多语言内容时考虑
维度
权衡信息丰富度与计算成本
许可条款
开源vs专有服务
最大Token
适合的上下文窗口
最重要的是考虑多语言支持和维度(和成本有关)。
最佳实践:为特定应用测试多个Embedding模型,评估在实际数据上的性能而非仅依赖通用标准。
2.2 常见选型 1.通用全能型
BGE-M3:北京智源研究院开发,支持多语言、混合检索(稠密+稀疏向量),处理 8K 上下文,适合企业级知识库。
NV-Embed-v2:基于 Mistral-7B,检索精度高(MTEB 得分 62.65),但需较高计算资源。
2.垂域特化型
中文场景: BGE-large-zh-v1.5 (合同/政策文件)、 M3E-base (社交媒体分析)。
多模态场景: BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征。
3.轻量化部署型
nomic-embed-text:768 维向量,推理速度比 OpenAI 快 3 倍,适合边缘设备。
gte-qwen2-1.5b-instruct:1.5B 参数,16GB 显存即可运行,适合初创团队原型验。
总的来说:
中文为主:BGE系列>M3E
多语言需求:BGE-M3>multilingual-e5
预算有限:开源模型,如Nomic Embed
2.3 Embedding models 对比案例 比如要对比 paraphrasemultilingual-MiniLM-L12-v2 和 text2vec-base-chinese-sentence 在自己数据集上的性能,这里选择开源数据集1 , 在实际开发时应该选择自己的数据集。使用如下代码:
代码的逻辑为:加载数据集(需要根据自己的数据格式调整),加载模型,分别用两个模型计算样本的嵌入向量,计算余弦相似度,根据匹配结果统计正确个数,即为准确率。
这里数据集为 The Stanford Question Answering Dataset 我只使用了dev-v2.0.json。
通过读取后数据集中每个样本格式如下:
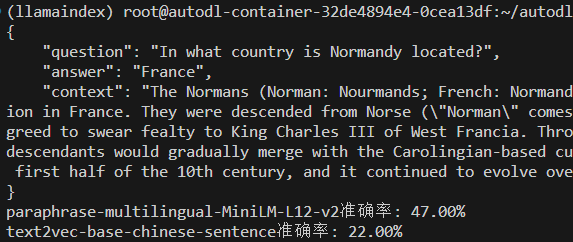
1 2 3 4 5 { "question" : "In what country is Normandy located?" , "answer" : "France" , "context" : "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\"Norman\" comes from \"Norseman\") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries." }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from sentence_transformers import SentenceTransformer, utilimport jsonimport numpy as npimport jsonwith open ("dev-v2.0.json" ) as f: squad_data = json.load(f)["data" ] qa_pairs = [] for article in squad_data: for para in article["paragraphs" ]: for qa in para["qas" ]: if not qa["is_impossible" ]: qa_pairs.append({ "question" : qa["question" ], "answer" : qa["answers" ][0 ]["text" ], "context" : para["context" ] }) print (json.dumps(qa_pairs[0 ], indent = 4 ))model1 = SentenceTransformer('/root/autodl-tmp/paraphrase-multilingual-MiniLM-L12-v2' ) model2 = SentenceTransformer('/root/autodl-tmp/text2vec-base-chinese-sentence' ) contexts = [item["context" ] for item in qa_pairs] context_embeddings1 = model1.encode(contexts) context_embeddings2 = model2.encode(contexts) def evaluate (model, query_embeddings, context_embeddings ): correct = 0 for idx, qa in enumerate (qa_pairs[:100 ]): sim_scores = util.cos_sim(query_embeddings[idx], context_embeddings) best_match_idx = np.argmax(sim_scores) if qa["answer" ] in contexts[best_match_idx]: correct += 1 return correct / len (qa_pairs[:100 ]) query_embeddings1 = model1.encode([qa["question" ] for qa in qa_pairs[:100 ]]) query_embeddings2 = model2.encode([qa["question" ] for qa in qa_pairs[:100 ]]) acc1 = evaluate(model1, query_embeddings1, context_embeddings1) acc2 = evaluate(model2, query_embeddings2, context_embeddings2) print (f"paraphrase-multilingual-MiniLM-L12-v2准确率: {acc1:.2 %} " )print (f"text2vec-base-chinese-sentence准确率: {acc2:.2 %} " )
通过这种方式可以对比两个模型在特定数据集上的匹配效果,text2vec-base-chinese-sentence更适合中文文本,所以它的效果差一些:
但Embedding模型的不同带来的影响时很小的,因为不同模型计算的两个句子之间的余弦相似的差别是不大的,比如下面的例子中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from llama_index.embeddings.huggingface import HuggingFaceEmbeddingimport numpy as npdef fun (model_name, documents, query ): embed_model = HuggingFaceEmbedding( model_name=model_name, device="cuda" , normalize=True , ) doc_embeddings = [embed_model.get_text_embedding(doc) for doc in documents] query_embedding = embed_model.get_text_embedding(query) similarity = np.dot(query_embedding, doc_embeddings[0 ]) return similarity if __name__ == "__main__" : documents = ["忘记密码如何处理?" , "用户账号被锁定" ] query = "密码重置流程" model_name = "/home/cw/llms/embedding_model/sungw111/text2vec-base-chinese-sentence" similarity = fun(model_name, documents, query) print (f"text2vec-base-chinese-sentence 结果: 相似度:{similarity:.4 f} " ) model_name = "/home/cw/llms/embedding_model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" similarity = fun(model_name, documents, query) print (f"paraphrase-multilingual-MiniLM-L12-v2 结果: 相似度:{similarity:.4 f} " )
输出如下:两个结果差别并不大