推导Transformer注意力机制的计算过程,解释训练和推理过程注意力计算的不同,解释为什么有kv-cache而没有q-cache
在LLM推理中最关键的就是下图中的Multi-Head Attention, 其主要的计算集中在左图中灰色的Linar(矩阵乘)和Scaled Dot-Product Attention 中的MatMul矩阵乘法:
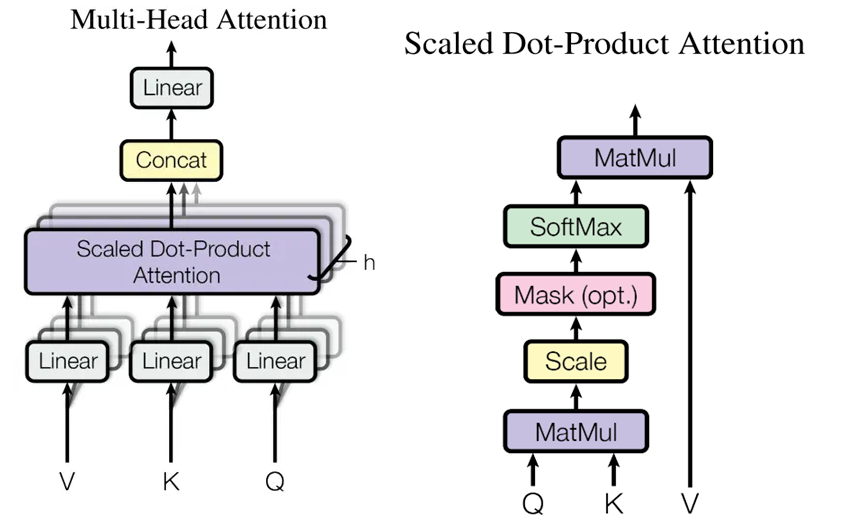
说明:
Multi-Head Attention: 输入$X$经过$W_Q, W_K, W_V$矩阵的线性变换, 对结果进行拆分后为每个注意力头生成一组输入$Q,K,K$, 经过计算每个注意力头输出一个注意力矩阵,拼接后生成总的注意力矩阵, 最后经过一个全连接层得到输出矩阵。
Scaled Dot-Product Attention 流程为 $Q,K$进行矩阵乘得到$QK^T$,接着除以$\sqrt{d_k}$使方差变小, 然后和因果掩码矩阵$Mask(opt.)$相乘, 最后经过$SoftMax(\cdot)$归一化后和$V$相乘。
注意力的计算公式如下:
- Attention不直接使用$X$,而是使用经过矩阵乘法生成的这三个矩阵,因为使用三个可训练的参数矩阵,可增强模型的拟合能力。
- $softmax(\cdot )$是归一化函数, 使结果更平滑。
- $d_k$是头维度,这个除法称为Scale, 当$d_k$很大时, $QK^T$的乘法结果方差变大, 进行Scale可以使方差变小, 训练时梯度更新更稳定。
- 因果掩码矩阵:因果掩码矩阵是一个上三角, 在解码器训练的过程中,不能让模型知道未来时间步的信息,否则就相当于告诉了模型的最终答案是什么。例如我们给解码器输入”I like eating pears”,当我们在计算’like’这个词与与其他词的注意力权重时,因为解码器是一个单词一个单词预测的,在预测’like’这个词时是不应该知道后面的单词,所以与’like’后面的单词不应该产生关联性。
一. 训练阶段
涉及的变量
参数 含义
B batch size
t 序列长度
$d_{model}$ 模型维度
h 注意力头数
$d_k$ $d_k = \frac{d_{model}}{h}$ 每个头的维度
假设$Batch_size=1$, 一次多头注意力的计算如下:
step1 输入Embedding
输入矩阵为
$X\in \mathbb{R}^{t\times d_{model}}$
step2 线性变换生成QKV
$Q,K,V$都是从同样的输入矩阵$X$线性变换而来:
其中$X \in \mathbb{R}^{t\times d_{model}}, W^Q,W^K,W^V \in \mathbb{R}^{d_{model} \times d_{model}}, Q,K,V\in \mathbb{R}^{t\times d_{model}}$
step3 多头拆分
$Q,K,V$先reshape成 $t \times h \times d_{k}$, 其中$h=\frac{d_{model}}{d_k}$, 接着转置为$h\times t \times d_k$
step4 缩放点积注意力
在训练时, 通常处理的是完整的序列, $Q,K,V$都是序列长度$\times$头维度($t\times d_k$)的矩阵,此时$K,Q,V\in \mathbb{R}^{t \times d_{k}}$。
把$Q,K,V$写成列向量形式:
其中$k_i,q_i,v_i \in \mathbb{R}^{1\times d_k},i=1,2,…,t$, 所以$Q,K,V\in \mathbb{R}^{t,d_{model}}$
$Q$和$K$装置的矩阵乘就变成了:
忽略除以$\sqrt{d_k}$(这只是一个常数, 不改变矩阵大小), 接着乘以因果掩码矩阵, 并进行归一化后结果为, 这里第$i$行的$SoftMax$简写成$S_i$, 结果为:
其中$m_i$表是第$i,\ i = 1,2,…,h$个注意力头的输出, 大小为$t\times d_{k}$
step5 拼接所有输出
拼接所有注意力头的输出:
经过拼接, 最终输出$M_{concat}$形状又变回$t \times d_{model}$
step6 全连接层(Projection)
其中$W^O\in \mathbb{R}^{d_{model} \times d_{model}}, M_{output}\in \mathbb{R}^{t\times d_{model}}$
以上的推导为了方便表示, 没有考虑batch_size, 如果加上batch_size, 各阶段计算如下:
| 阶段 | 参数 | 输入 | 输出 |
|---|---|---|---|
| step1 | $Embed(\cdot)$ | $B$个字符串 | $X\in \mathbb{R}^{B\times d_{model}}$ |
| step2 | $W^Q,W^K,W^V \in \mathbb{R}^{d_{model} \times d_{model}}$ | $X\in \mathbb{R}^{B\times t\times d_{model}}$ | $Q,K,V\in \mathbb{R}^{B\times t\times d_{model}}$ |
| step3 | $Reshape(\cdot)$ | $Q,K,V\in \mathbb{R}^{B\times t\times d_{model}}$ | $Q,K,V\in \mathbb{R}^{ B\times h\times t\times d_k}$ |
| step4 | $SoftMax(Mask(\frac{QK^T}{\sqrt{d_k}}))V$ | $Q,K,V\in \mathbb{R}^{ B\times h\times t\times d_k}$ | $M_i \in \mathbb{R}^{B\times t\times d_k}, i = 1,2,…,h$ |
| step5 | $Concat(\cdot)$ | $M_i \in \mathbb{R}^{B\times t\times d_k}, i = 1,2,…,h$ | $M_{concat}\in \mathbb{R}^{B \times t\times d_{model}}$ |
| step6 | $W^O$ | $M_{concat}\in \mathbb{R}^{B \times t\times d_{model}}$ | $M_{output} \in \mathbb{R}^{B\times t \times d_{model}}$ |
二. 推理阶段
训练阶段是整个序列一起计算, 并不需要$kv-cache$
推理阶段, 我们实际是要预测第$L$个token, 即输入只有$q_L$, 公式$(5)$只需要算出矩阵的最后一行, 所以只需要当前的$q_L$, 不需要缓存之前的$Query$, 所以没有Q-Cache, 从公式也可以看出, 在预测第$t$个token时, K,V的维度为$L\times d_k$, Q的维度为$1\times d_k$ 所以需要$KV-Cache$而不需要$Q-Cache$
在batch_size=1时, 推理过程如下:
step1 输入
假设当前要预测第$t$个token$x_t$, 则输入是上一步(第$t-1$步)的输出$x_{t-1}$的Embedding
step2 计算$q_t,k_t,v_t$
从输入$x_t$线性变换得到$q_t,k_t,v_t$:
其中$x_t\in \mathbb{R}^{1\times d_{model}}, W^Q,W^K,W^V \in \mathbb{R}^{d_{model} \times d_{model}}, q_t,k_t,v_t \in \mathbb{R}^{1\times d_{model}}$
step3 多头拆分
$q_t,k_t,v_t$先reshape成 $1 \times h \times d_{k}$, 其中$h=\frac{d_{model}}{d_k}$, 接着转置为$h\times 1 \times d_k$, 分发到不同的注意力头, 每个头拿到一个输入$q_t,k_t,v_t \in \mathbb{R}^{1\times d_k}$
step4 缩放点积注意力
自回归推理中我们只需要预测当前第$t$个token, 所以只需要计算公式$(5)$的最后一行, 前$t-1$个token的$k,v$我们都缓存了, 读取后和新计算的$k_t,v_t$拼接可以得到:
其中$q_t,k_i,v_i \in \mathbb{R}^{1\times d_k},i=1,2,…,t$, 所以$K,V\in \mathbb{R}^{t,d_k}, Q\in \mathbb{R}^{1\times d_k}$
$Q$和$K$装置的矩阵乘就变成了:
忽略除以$\sqrt{d_k}$(这只是一个常数, 不改变矩阵大小), 推理过程需要关注整个序列, 所以不需要乘以因果掩码矩阵, 结果进行归一化后为:
其中$M_i$表示第$i,\ i = 1,2,…,h$个注意力头的输出, 大小为$1\times d_{k}$
step5 拼接所有输出
拼接所有注意力头的输出:
经过拼接, 最终输出$M_{concat}$ 形状又变回 $1 \times d_{model}$
以上的推导为了方便表示, 没有考虑batch_size, 如果加上batch_size, 各阶段计算如下:
| 阶段 | 参数 | 输入 | 输出 |
|---|---|---|---|
| step1 | $Embed(\cdot)$ | $B$个字符串的第$t-1$个字符的嵌入向量 | $x_t\in \mathbb{R}^{B\times 1 \times d_{model}}$ |
| step2 | $W^Q,W^K,W^V \in \mathbb{R}^{d_{model} \times d_{model}}$ | $x_t \in \mathbb{R}^{B\times 1\times d_{model}}$ | $k_t, v_t, q_t\in \mathbb{R}^{B\times 1 \times d_{model}}$ |
| step3 | $Reshape(\cdot)$ | $k_t, v_t, q_t\in \mathbb{R}^{B\times 1 \times d_{model}}$ | $k_t, v_t, q_t\in \mathbb{R}^{ B\times h\times 1\times d_k}$ |
| step4 | $SoftMax(\frac{QK^T}{\sqrt{d_k}})V$ | $K,V\in \mathbb{R}^{ B\times h\times t\times d_k}, q_t\in \mathbb{R}^{B\times 1 \times d_{model}}$ | $M_i \in \mathbb{R}^{B\times 1\times d_k}, i = 1,2,…,h$ |
| step5 | $Concat(\cdot)$ | $M_i \in \mathbb{R}^{B\times 1\times d_k}, i = 1,2,…,h$ | $M_{concat}\in \mathbb{R}^{B \times 1\times d_{model}}$ |
| step6 | $W^O\in \mathbb{R}^{d_{model}\times d_{model}}$ | $M_{concat}\in \mathbb{R}^{B \times 1 \times d_{model}}$ | $M_{output} \in \mathbb{R}^{B\times 1 \times d_{model}}$ |
