介绍LlamaIndex的安装以及如何使用LlamaIndex快速搭建RAG应用。
一. 什么是LlamaIndex
LlamaIndex是用于LLM应用程序的数据框架,用于注入,结构化,并访问私有或特定领域数据。也就是解决LLM和Data之间的衔接问题。
上下文增强。 LLM 提供了人类和数据之间的自然语言接口。LLM 在大量公开可用的数据上进行了预训练,但它们并未在您的数据上进行训练。您的数据可能是私有的,或特定于您正在尝试解决的问题。它可能隐藏在 API 之后、SQL 数据库中,或者困在 PDF 和幻灯片中。上下文增强最流行的例子是检索增强生成(Retrieval-Augmented Generation,简称 RAG),它在推理时将上下文与 LLM 结合。
LlamaIndex 提供了构建任何上下文增强用例的工具,从原型到生产。在 RAG 中,数据首先被加载并准备好用于查询或“索引”。用户查询作用于索引,索引将数据过滤到最相关的上下文。然后,此上下文和您的查询会与提示一起发送给 LLM,LLM 会提供响应。
二. RAG核心概念
RAG可用下图表示:
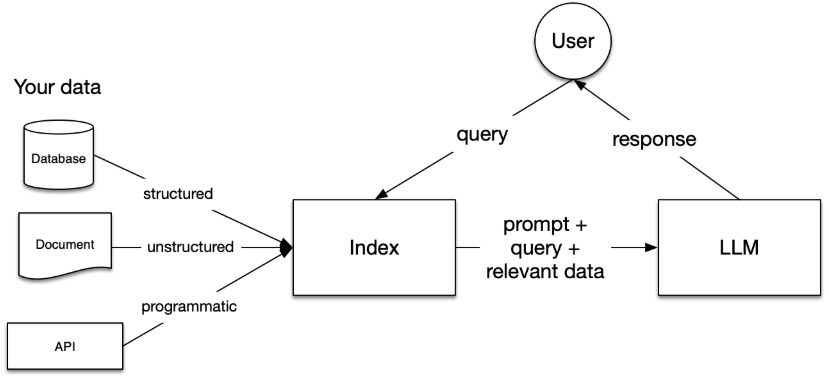
2.1 RAG的5个阶段
1. 加载。 将数据从其所在地(如文本文件,PDF,数据库,API等)加载到本RAG工作流中,LlamaIndex提供了data connector用于加载各种格式的数据。
2. 索引。 创建一个允许查询数据的数据结构。对于LLM,指的是创建向量嵌入(即将文本转化为向量),并生成对应的索引。以便轻松准确地查找与上下文相关的数据。
3. 存储。 存储文本向量以及索引,以免重复索引。
4. 查询。 对于任何给定的索引策略,您都可以通过多种方式利用 LLM 和 LlamaIndex 数据结构进行查询,包括子查询、多步查询和混合策略。
5. 评估。 任何流程中的关键一步是检查它相对于其他策略或在您进行更改时的有效性。评估提供了关于您的查询响应有多准确、忠实和快速的客观衡量标准。
5个阶段是依次进行的。

2.2 RAG的核心阶段
RAG中最重要的两个阶段为索引和查询阶段。
1. 索引阶段。 LlamaIndex通过提供 Data connectors(数据连接器)和 Indexes(索引)帮助开发者构建知识库。该阶段会用到如下工具或组件:
Data connectors(数据连接器)。它负责将来自不同数据源的不同格式的数据注入,并转换为LlamaIndex支持的文档(document)形式,其中包含了文本和元数据。
注:概念Documents/Nodes Documents是LlamaIndex中容器的概念,它可以包含任何数据源,包括PDF, API, 数据库,Node是LlamaIndex中数据的最小单元,代表了一个Document的分块,它还包含了元数据,以及与其他Node的关系信息。这使得更精确的检索操作成为可能。
Data Index(数据索引)。LlamaIndex提供的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而且高效,最常用的索引是向量存储索引VectorStoreIndex。
2. 查询阶段。 在查询阶段,RAG管道根据用户查询,检索最相关的上下文,并将其与查询一起,传递给LLM,以合成响应。这是LLM能够获得不在器原始训练数据中的最新知识,同时也减少了虚构内容(大模型幻觉)。该阶段关键在于检索,编排和基于知识库的推理。
LlamaIndex提供可组合的模块,帮助开发者构建和集成RAG管道,用于问答,聊天机器人或作为代理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库机型推理。
该阶段的构建块包括:
- Retrivers 检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。
- Node Postprocessors Node后处理器。它对一系列文档节点(Node)实施转换,过滤或排名。
- Resopnse Synthesizers 响应合成器。 它基于用户的查询,和一组检索到的文本块(形成上下文),利用LLM生成响应。
RAG管道包括:
- Query Engines 查询引擎(端到端管道)。允许用于基于知识库,以自然语言提问,并获得回答,以及相关的上下文。
- Chat Engines 聊天引擎(端到端管道)。允许用于基于知识库进行对话(多轮对话)。
- Agent 代理。它是一种由LLM驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这位其提供了处理更复杂任务的额外灵活性。
三. LlamaIndex 快速构建RAG
参考官网: Starter Tutorial (Using OpenAI) - LlamaIndex
中文文档: LlamaIndex - LlamaIndex 框架
3.1 LlamaIndex 的安装
注意一定要用py3.12,笔者试过了,它最不会出问题, 并且安装最新的LlamaIndex, 不要加版本号。
1 | conda create -n llamaindex python==3.12 -y # 创建环境 |
3.2 快速开始
首先下载千问大模型Qwen1.5-1.8B-Chat
使用如下代码快开始一个LlamaIndex样例,需要安装额外的包
1 | pip install llama_index.llms.huggingface |
1 | from llama_index.core.llms import ChatMessage |
运行后结果如下图:
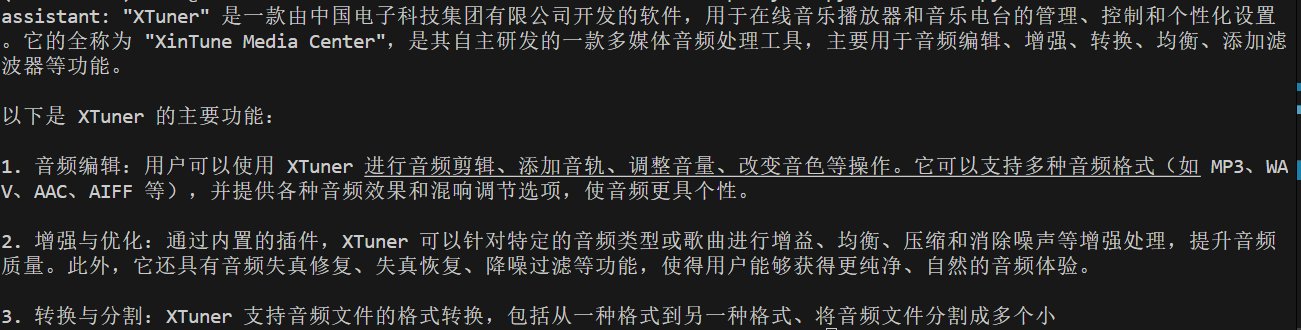
但此时是没有知识库的,所以出现了大模型你幻觉。
3.3 快速构建RAG
先下载嵌入模型sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
这里用huggingface加载模型,所以一定要下载sentence-transformer模型,不能下成huggingface模型。
还要补充安装包:
1 | pip insatll llama_index.embeddings.huggingface |
接下来使用LlamaIndex构建RAG,这里使用的是xtuner项目中的readme.md 代码如下:
1 | from llama_index.embeddings.huggingface import HuggingFaceEmbedding |
运行后输出如下

可以看到,大模型根据输入的知识给出正确的输出。
