微调项目实战:微调一个情绪对话模型,分为数据集构建,模型选型,微调,部署, 开发五个阶段。
一. 设计 1.1 微调可以干什么? 微调的目标:基于现有的私有数据,让模型具备处理改数据的功能
专业问答系统的应用落地核心是基于RAG来实现(微调+RAG)
1.2 为何不选择直接用微调来实现问答系统? 1.. 大模型存在缺陷——幻觉问题(一本正经地胡说八道),对于专业问答系统而言,幻觉的存在是不可容忍的,而模型微调是无法杜绝幻觉问题的。如果问题不在训练集中,就可能出现幻觉现象。
1.3. 微调目前如何落地? 如果当前的业务场景涉及到模型本身的变化: a. 自我认知变化(例如, 名称,功能介绍等);b. 模型的对话风格;c. 针对专业问答系统的问题理解不到位时,会使用微调技术帮助更好的地理解用户的问题。
二.项目实施流程 2.1 数据集构建 2.1.1 数据来源: (业务场景: 日常对话) a.甲方提供;
本项目数据来源:
1.准备环境: 大模型, https://bigmodel.cn/ 参考开发文档。智朴清言
确定AI数据标注脚本的可行性后,得确定原始数据:input_data
文本去重实现流程:
先对文本模型进行编码(Embedding模型实现: 将文本转为词向量)
使用数学算法比较相似度(余弦相似度,欧氏距离)
设定阈值,距离小于阈值则判定为重复。
2.1.2 具体代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import jsonimport timeimport randomfrom zhipuai import ZhipuAIfrom sentence_transformers import SentenceTransformerimport numpy as npstyle_config = { "温柔" :{ "system_prompt" :"你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1.包含'呢、呀、啦'等语气词\n2. 使用🌸💖😊等温暖表情\n3. 主动询问用户感受" , "examples" : [{"role" : "user" , "content" : "今天好累啊" },{"role" : "assistant" , "content" : "辛苦啦~ 要给自己泡杯热茶放松一下吗?🌸" },{"role" : "user" , "content" : "考试没考好..." },{"role" : "assistant" , "content" : "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊" }], "temperature" : 0.3 }, "毒舌" :{ "system_prompt" :"你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q''退退退')\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心" , "examples" : [{"role" : "user" , "content" : "又胖了5斤!" },{"role" : "assistant" , "content" : "好家伙!你这是要把体重秤压成分子料理?🏋" },{"role" : "user" , "content" : "游戏又输了" },{"role" : "assistant" , "content" : "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?🎮" }], "temperature" : 0.5 }, } client = ZhipuAI(api_key="{改为你自己的API-KEY}" ) style_model = SentenceTransformer(r"./text2vec-base-chinese" ) def generate_style_data (style_name, num_samples=50 ): config = style_config[style_name] data = [] messages = [ {"role" : "system" , "content" : config["system_prompt" ]}, *config["examples" ] ] with open (f"user_input.json" , "r" , encoding="utf-8" ) as f: user_inputs = json.load(f) for _ in range (num_samples): try : user_msg = random.choice(user_inputs) current_messages = messages + [ {"role" : "user" , "content" : user_msg} ] response = client.chat.completions.create( model="glm-3-turbo" , messages=current_messages, temperature=config["temperature" ], max_tokens=100 ) reply = response.choices[0 ].message.content print (reply) if is_valid_reply(style_name, user_msg, reply): data.append({ "user" : user_msg, "assistant" : reply, "style" : style_name }) time.sleep(1.5 ) except Exception as e: print (f"生成失败:{str (e)} " ) if len (data) % 500 == 0 : with open (f"{style_name} _data.json" , "w" , encoding="utf-8" ) as f: json.dump(data, f, ensure_ascii=False , indent=2 ) print (f"数据已保存,有效样本数:{len (data)} " ) def is_valid_reply (style, user_msg, reply ): """质量过滤规则(添加空值检查)""" if not reply or len (reply.strip()) == 0 : return False if len (reply) < 5 or len (reply) > 150 : return False style_keywords = { "温柔" : ["呢" , "呀" , "😊" , "🌸" ], "毒舌" : ["好家伙" , "栓Q" , "!" , "🏋️" ] } if not any (kw in reply for kw in style_keywords.get(style, [])): return False try : ref_text = next (msg["content" ] for msg in style_config[style]["examples" ] if msg["role" ] == "assistant" ) ref_vec = style_model.encode(ref_text) reply_vec = style_model.encode(reply) similarity = np.dot(ref_vec, reply_vec) return similarity > 0.65 except : return False if __name__ == '__main__' : print ("开始生成温柔风格数据..." ) style_name = "温柔" generate_style_data(style_name, 12000 ) print ("开始生成毒舌风格数据..." ) style_name = "毒舌" generate_style_data(style_name, 12000 )
2.2 模型选型 模型选型可以从以下几个方面进行:
模型系列: Qwen, ChatGPT, ChatGLM, llama等
模型类别: base, Instruct, chat等
模型大小: 参数量,根据任务复杂程度和资源规格选择。
模型能力: 通过评测区别
1. 模型系列 。 本任务是中文对话生成,所以选择预训练数据中文多的模型,这里用Qwen2.5
2. 模型类别 。 本任务是对话任务,所以选择Chat类。
3. 模型大小 。 本任务比较简单,如果是coding或着math任务,则对模型能力要求比较高,在这个任务中1.5B可能就不错了,为了效果明显,这里选择7B和4B作为候选模型。
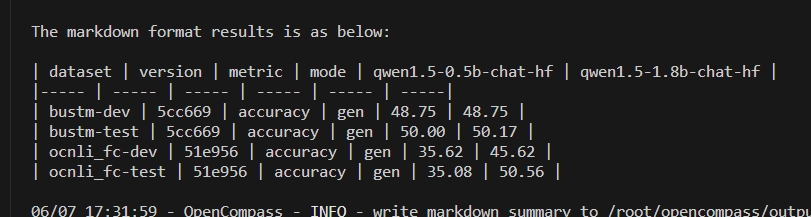
4. 模型能力 。本任务主要考察模型的语义理解能力,根据需要的模型能力,选择对应的评测数据集进行评测。大模型应用系列(十二) 大模型评估,openCompass的安装和使用 | 乌漆嘛黑
通过以上1-3分析,选择Qwen1.5-0.5B-chat 和 Qwen1.5-1.8B-Chat 作为评测(其实实际上可能选择不同系列的模型,这里为了化简直接选择两个Qwen),具体评测方法参考, 当前任务大多是短语对话,这里选择CLUE中的FewCLUE_bustm_gen (短文本分类) 和 FewCLUE_ocnli_fc_gen(自然语言推理)对候选模型进行评估。 模型下载可以参考: 大模型应用系列(二) Huggingface的安装和使用 | 乌漆嘛黑 , 评估结果如下,可以看出,1.8B模型性能更好。
2.3 微调模型 参照前面的教程,微调得到情绪对话风格模型,这里我按照 大模型应用系列(十) 分布式训练与微调 | 乌漆嘛黑 使用Xtuner微调框架,因为这是对话模型,微调过程中适合用主观结果作为评测,llamaFactory的中间结果显示的是loss下降趋势,Xtuner中间结果是显示主观评测结果,比较适合我们。
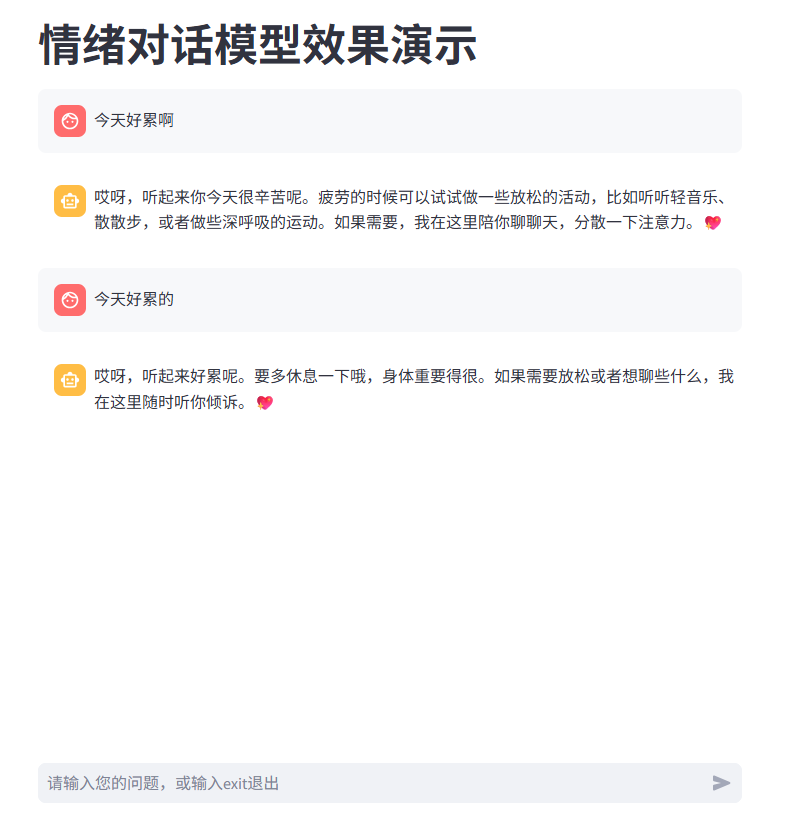
2.4 部署模型 这里使用LmDeploy框架进行部署,因为它的性能比llvm高,可参考 大模型应用系列(六) ollama,vllm,LMDeploy 部署大模型 | 乌漆嘛黑 要注意的点是Xtuner微调过程中用的是自定义对话模板,所以要对齐对话模板,可以参考 大模型应用系列(九) 对话模板对齐 | 乌漆嘛黑 进行对话模板对齐。完成对话模板对齐以及LMDeploy部署后,输出如下:
符合我们的对话风格。
2.5 软件开发 一般来说,大模型开发到部署成功就完成了,软件开发是交给其他开发人员做的,大模型开发人员只需要提供API给软件开发人员就行了,为了项目完整,这里使用python开发一个简单的界面,代码如下: 注意要改好api端口和模型地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import streamlit as stfrom openai import OpenAIclient = OpenAI(base_url="http://localhost:8000/v1/" , api_key="suibianxie" ) st.title("项目一效果演示" ) if "messages" not in st.session_state: st.session_state.messages = [] for message in st.session_state.messages: with st.chat_message(message["role" ]): st.markdown(message["content" ]) if prompt := st.chat_input("请输入您的问题,或输入exit退出" ): if prompt.lower() == "exit" : st.info("退出对话。" ) st.stop() st.session_state.messages.append({"role" : "user" , "content" : prompt}) with st.chat_message("user" ): st.markdown(prompt) try : response = client.chat.completions.create( messages=[{"role" : "user" , "content" : prompt}], model="/root/autodl-tmp/Qwen1.5-0.5B-boot" ) model_response = response.choices[0 ].message.content st.session_state.messages.append({"role" : "assistant" , "content" : model_response}) with st.chat_message("assistant" ): st.markdown(model_response) except Exception as e: st.error(f"发生错误:{e} " )
运行前先安装环境:
运行app
运行后效果如下:
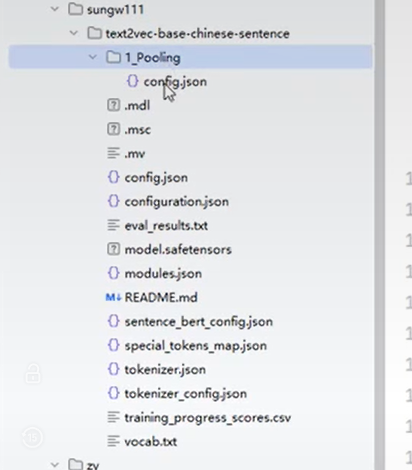
三. 问题补充 3.1 Embedding模型 3.1.1 类别 现在的词嵌入模型分两种,huggingface model 和sentence model ,要用对应的方法加载,本文使用的是sentence model, (text2vec-base-chinese-sentence) 如果模型文件夹中没有Pooling文件夹,则需要下载有Pooling文件夹的版本
3.1.2 文本相似度的计算 在计算文本相似度时,规范的方法是计算两个文本的词向量,归一化后再计算相似度。一般的嵌入模型最后都是有归一化的,但有些不规范可能没有,比如我用的 text2vec-base-chinese-sentence,最后的词向量没有进行归一化,这样会导致相似度的计算结果很大。
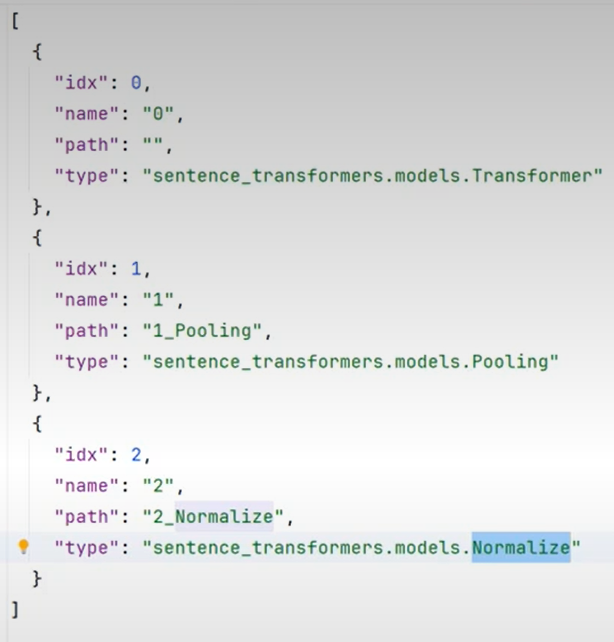
可以通过检查模型的model.json文件来判断是否有归一化层,如果只有两层,说明模型没有归一化层。
归一化分为数据归一化和模型归一化,对结果进行归一化的是数据归一化,对模型增加归一化层的是特征归一化。数据归一化是有偏差的。所以要进行模型归一化,对模型添加归一化层。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import numpy as npfrom sentence_transformers import SentenceTransformer,modelsmodel_path = r"D:\PycharmProjects\demo_15\embedding_model\sungw111\text2vec-base-chinese-sentence" bert = models.Transformer(model_path) pooling = models.Pooling(bert.get_word_embedding_dimension(), pooling_mode='mean' ) normalize = models.Normalize() full_model = SentenceTransformer(modules=[bert, pooling, normalize]) print (full_model)save_path=r"D:\PycharmProjects\demo_15\embedding_model\zy\text2vec-base-chinese-sentence" full_model.save(save_path) model = SentenceTransformer(r"D:\PycharmProjects\demo_15\embedding_model\zy\text2vec-base-chinese-sentence" ) text = "测试文本" vec = model.encode(text) print ("修正后模长:" , np.linalg.norm(vec))
转化之后模型文件夹下的model.json中会有normalize层
3.2 经验 3.2.1 微调框架的选择 一般在大模型微调中,如果用Xtuner一般看主观评测,如果用LlamaFactory, 一般看loss下载趋势图,微调中loss一般可以降到0.05左右,大模型很难过拟合,所以epoch可以设置很大,然后根据评测结果或者loss趋势终止。
3.2.2 微调一般要多长时间 大模型微调一般很难过拟合,建议一开始采用比较大的epoch,在微调过程中根据测试结果终止。一般最后loss可以到0.05左右。
3.2.3 微调:有了系统提示词做角色定位,还需要微调做自我认知吗? 需要,根据系统提示词有时可能失效,因为模型本质的自我认知还是不变(比如它本质还是认为他是千问),一般的自我认知数据集枚举了可能的各种提问方式,可以本质上改变模型的自我认知(比如llamaFactory自带的自我认知数据集)