简单介绍大模型评估常用的指标和数据集,以及评估工具opencompass的安装和使用。
一. 生成式大模型的评估指标及OpenCompass介绍
1.1 核心评估指标
OpenCompass支持以下主要评估指标,覆盖生成式大模型的多样化需求:
准确率(Accuracy): 用于选择题或分类任务,通过比对生成结果与标准答案计算正确率。在OpenCompass中通过metric=accurancy配置。
困惑度(Perplexity, PPL): 衡量模型对候选答案的预测能力,适用于选择题评估。需使用ppl类型的数据集配置(如ceval_ppl)。
生成质量(GEN): 通过文本生成结果提取答案,需结合后处理脚本解析输出。使用gen类型的数据集(如ceval_gen),配置metric=gen并指定后处理预测。
ROUGE/LCS: 用于文本生成任务的相似度评估,需安装rouge==1.0.1依赖,并在数据配置中设置metric=rouge
条件对数概率(CLP): 结合上下文计算答案的条件概率,适用于复杂推理任务,需在模型配置中启用use_logprob=True
1.2 支持的开源评估数据集及使用差异
OpenCompass内置超过70个数据集,覆盖五大能力维度:
知识类: C-Eval(中文考试题),CMMLU(多语言知识问答),MMLU(英文多选题)。
推理类: GSM8K(数学推理),BBH(复杂推理链)。
语言类: CLUE(中文理解),AFQMC(语义相似度)。
代码类: HumanEval(代码生成),MBPP(编程问题)。
多模态类: MMBench(图像理解),SEED-Bench(多模态问答)。
1.3 OpenCompass介绍
OpenCompass是一个开源项目,旨在为机器学习和自然语言处理领域提供多功能,易于使用的工具和框架。其中包含的多个开源模型和开源数据集(BenchMarks), 方便进行模型的效果评测。
1.4 支持的开源评估数据集及使用差异
数据集区别与选择
评估范式差异:
_gen后缀数据集: 生成式评估,需后处理提取答案(如ceval_gen)
_ppl后缀数据集: 困惑度评估,直接比对选项概率(如ceval_ppl)
领域覆盖:
C-Eval: 侧重中文STEM和社会科学知识,包含1.3万到选择题
LawBench: 法律领域专项评估,需额外克隆仓库并配置路径。
1.5 在开源数据集上评估的必要性
在选型阶段,通过评估选择合适的模型。
在评估阶段,在公开数据集上评估可以判断模型微调后是否保持原有基本能力,而不至于过拟合。但某些场景模型往往需要过拟合: 比如应用中指定模型能回答的某些问题,可以通过应用层筛选。对于法律,医疗相关的问题,一般要训练充分,不必关注它的其他能力。
二. OpenCompass的安装和使用
2.1 OpenCompass的安装
参考文档: 欢迎来到 OpenCompass 中文教程! — OpenCompass 0.4.2 文档
注意: 安装的python必须是3.10版本。虽然官网没有特别说明,但我试过其他版本都不能用。
官网提供了pip安装和源码安装两种方式,在评测时可能需要写配置文件,需要源码,所以建议从源码安装。
1 | # 创建并激活虚拟环境 |
2.2 数据集准备
OpenCompass准备了评估需要用到的常见数据集,如果要获取大多数数据集,可以:
在OpenCompass项目根目录下运行下面命令,运行下面命令
1 | wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip |
执行后在根目录会产生data文件夹,内容如下,包含了常见的数据集:
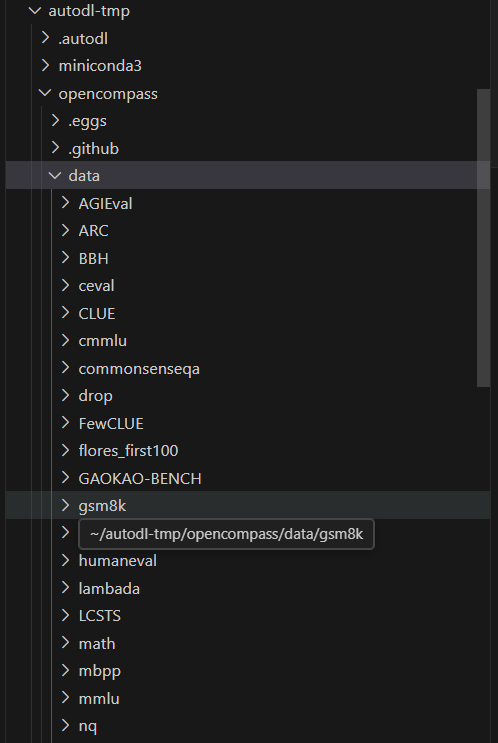
如果需要使用 OpenCompass 提供的更加完整的数据集 (~500M),可以使用下述命令进行下载和解压:
1 | wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip |
我服务器磁盘有限,就没有下载完整数据集。
2.3 配置评估任务
目前opencompass支持三种配置方式的评估任务,以下命令都在opencompass根目录下执行。
2.3.1 命令行(自定义HF模型)
对于HuggingFace模型, 用户可以通过命令行直接设置模型参数,这种方式比较简单,无需额外的配置文件,但缺点是每次只能在一个或多个数据集上评估一个模型,并且模型必须是huggingface模型。比如评估Qwen2.5-7B-Instruct模型在demo_gsm8k_chat_gen demo_math_chat_gen上的效果,可以用如下命令:
1 | python run.py --datasets demo_gsm8k_chat_gen demo_math_chat_gen --hf-path /root/autodl-tmp/Qwen2.5-7B-Instruct --debug |
我的安装版本中会报错AttributeError: module ‘torch’ has no attribute ‘device’,解决方式见 3.1, 解决后开始评估,如下图:
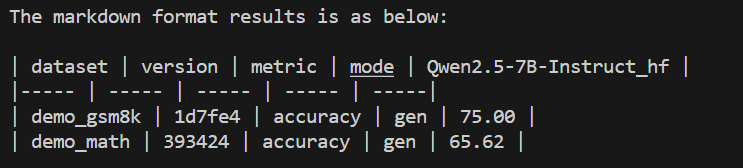
评估结束后会输出以下结果:
同时会在opencompass根目录下生成文件夹outputs用于保存输出,结构如下:
1 | outputs/default/ |
2.3.2 命令行结合配置文件
首先查看
首先查看opencompass支持的模型和数据集。模型和数据集的配置文件预存于 configs/models 和 configs/datasets 中。用户可以使用tools/list_configs.py 查看或过滤当前可用的模型和数据集配置 。
1 | 列出所有配置, 内容过多,直接输出到根目录下的output.txt文件中 |
输出中包含opencompass支持的所有模型和数据集,以及他们对应的配置文件,这相当于一个字典比如我们要评估Qwen2.5-7B-Instruct Qwen2.5-7B-Instruct模型在demo_gsm8k_chat_gen demo_math_chat_gen上的效果,output.txt的对应内容如下:

我们先去对应的配置文件下,改好配置文件,然后再python run.py命令中输入的是前面的模型名称,opencompass就会根据模型名称找到相对应的配置文件。
opencompass/opencompass/configs/models文件夹下找到对应的模型配置文件,这里要修改的是hf前缀的文件,将配置文件中的模型路径改为我们自己的模型路径, 比如hf_qwen2_5_0_5b_instruct.py修改如下:
1 | from opencompass.models import HuggingFacewithChatTemplate |
hf_qwen2_5_7b_instruct.py 同样修改,注意,可能opencompass 支持qwen, qwen2.5, 但不支持qwen1.5,如果想评估,qwen1.5, 可以选择要给qwen的配置文件,但再命令行中要输入选择的那个qwen的模型名称。也就是说--Model是output.txt中的Mode一列的值,真正的模型路径是在output.txt中path一列的值。
配置完成后使用如下命令
1 | python run.py --models hf_qwen2_5_0_5b_instruct hf_qwen2_5_7b_instruct --datasets demo_gsm8k_chat_gen demo_math_chat_gen --debug |
成功执行后开始评估:
显存使用情况如下,可以根据显存使用情况指定修改batch_size:
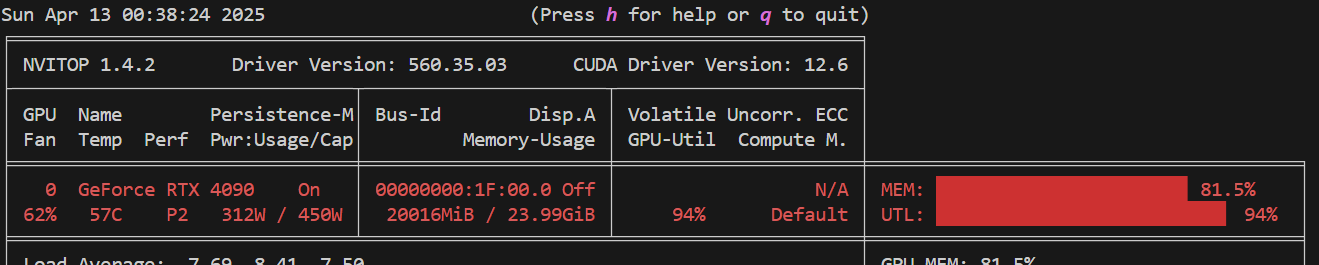
如果你有多张卡,并评估多个模型,则会同时评估多个模型,每个模型用1张卡。
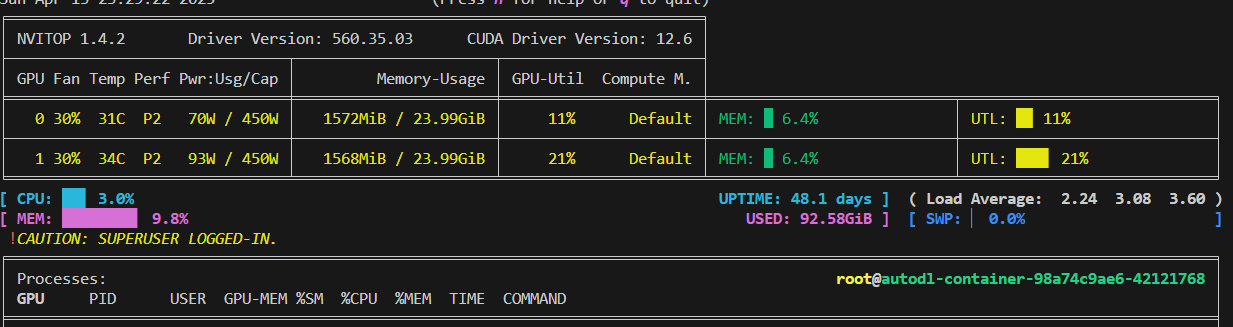
最终结果如下,同时会在opencompass根目录下生成文件夹outputs用于保存输出。

2.3.3 python脚本+配置文件
除了通过命令行配置实验外,OpenCompass 还允许用户在配置文件中编写实验的完整配置,并通过run.py 直接运行它。配置文件是以 Python 格式组织的,并且必须包括 datasets 和 models 字段。 其实他就是写一个python脚本去加载修改好的配置文件,所以先跟2.3.2一样修改配置文件,然后使用如下代码:
1 | from mmengine.config import read_base |
将该文件保存到opencompass/opencompass/configs目录下
直接运行:
1 | python /root/autodl-tmp/opencompass/opencompass/configs/run.py --debug |
2.3.4 多卡评估
在评估配置文件中指定run_cfg=dict(num_gpus=2)参数即可,其他操作同上。这里只在两个数据集上评估一个模型。
修改hf_qwen2_5_0_5b_instruct.py,如下:
1 | from opencompass.models import HuggingFacewithChatTemplate |
指令如下:
1 | python run.py --models hf_qwen2_5_0_5b_instruct --datasets demo_gsm8k_chat_gen demo_math_chat_gen --debug |
我一开始总是报错FileNotFoundError: Prediction files not found: neither outputs/default/20250413_233935/predictions/qwen2.5-0.5b-instruct-hf/demo_gsm8k.json nor outputs/default/20250413_233935/predictions/qwen2.5-0.5b-instruct-hf/demo_gsm8k_0.json exists ,后来我把其他日志目录下的对应文件复制到新的目录下,就正常运行了。
GPU使用情况如下图: 两张GPU都用上了。
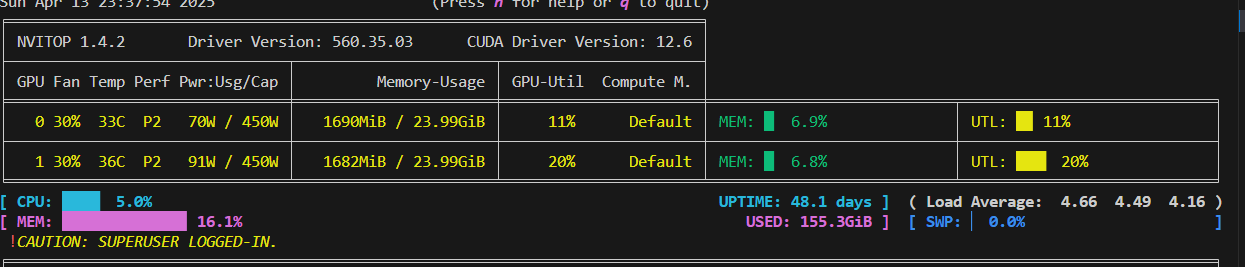
2.3.5 使用LMDeploy或vllm加速评估
目前opencompass支持vllm和LMDeploy加速评估。这里受用LMDeploy。
首先在当前环境安装LMDdeploy:
1 | pip install LMDeploy |
接着修改配置文件,要修改LMDeploy对应的配置文件,这里修改的是/root/autodl-tmp/opencompass/opencompass/configs/models/qwen2_5/lmdeploy_qwen2_5_0_5b_instruct.py
1 | from opencompass.models import TurboMindModelwithChatTemplate |
命令行运行
1 | python run.py --models lmdeploy_qwen2_5_0_5b_instruct --datasets demo_gsm8k_chat_gen demo_math_chat_gen --debug |
速度会肉眼可见地变快。
三. 遇到的问题以及解决方法
3.1 torch 版本问题
报错 [AttributeError: module 'torch' has no attribute 'device']) ,原因是torch版本不对,我虚拟环境版本是2.6.0,一般用2.5比较好,在opencompass/requierments/runtime.txt 中需改torch>=1.13.1为torch==2.5.1, 把原来环境删除,重新执行2.1安装步骤。
