介绍量化的概念,使用lmdeploy进行模型量化与kv-cache量化部署。
一. 概述
1.1 大模型推理
- 内存开销巨大
- 庞大的参数量,7B模型权重就需要14+GB显存
- 采用自回归生成token,需要kv-cache,带来巨大的显存开销
- 动态shape
- 请求数不固定
- Token逐个生成,且数量不定
- 相对视觉模型,LLM结构简单
- Transformer结构,大部分是decoder-only结构。
1.2 模型部署
定义:
将训练好的模型在特定的软硬件环境中启动的过程,使模型能够接收输入并返回预测结果;为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩(剪枝,量化,知识蒸馏)和硬件加速。
产品形态
云端,边缘计算端,移动端
计算设备
CPU, GPU, NPU, TPU等。
1.3 大模型部署挑战
设备
如何应对巨大的存储问题?低存储设备(消费级显卡,手机等)如何部署?
推理
- 如何加速token的生成
- 如何解决动态shape,让推理可以不间断
- 如何有效管理和利用显存
服务
- 如何提升系统整体吞吐量?
- 对于个体用户,如何降低相应时间?
1.4 大模型部署方案
常见技术
- 张量并行
- transformer计算和访存优化
- 低比特量化
- Continuous Batch
- Page Attention
- Blocked kv-cache
部署方案
- huggingface transformers
- 专门的推理加速框架
| 云端 | 移动端 |
|---|---|
| lmdeploy, vllm, tensorrt-llm,deepspeed | llama.cpp, mlc-llm |
二. LMDeploy简介
LMDeploy是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化,推理和服务。
项目地址: InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.
中文文档: 欢迎来到 LMDeploy 的中文教程! — lmdeploy
2.1 核心功能
- 高效的推理: LMDeploy开发了continus Batch, Blocked KV-cache,动态拆分和融合,张量并行,高效的计算kernel等重要特性。推理性能是vLLM的1.8倍。
- 可靠的量化: LMDeploy支持权重量化和kv量化。4bit模型推理效率是FP16下的2.4倍。量化模型的可靠性已通过 OpenCompass评测得到充分验证。
- 便捷的服务: 通过请求分发服务,LMDeploy支持多模型在多机,多卡上的推理服务。
- 有状态推理: 通过缓存多轮对话过程中attention的KV,记住对话历史,从而避免重复处理历史绘画,显著提升长文本多轮对话场景中的效率。
- 卓越的兼容: LMDeploy 支持 KV-cache量化,AWQ, Automatic Prefix Caching同时使用
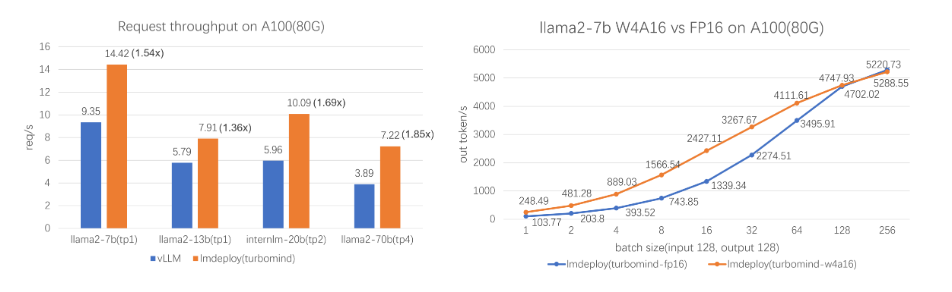
2.2 性能
LMDeploy TurboMind 引擎拥有卓越的推理能力,在各种规模的模型上,每秒处理的请求数是 vLLM 的 1.36 ~ 1.85 倍。在静态推理能力方面,TurboMind 4bit 模型推理速度(out token/s)远高于 FP16/BF16 推理。在小 batch 时,提高到 2.4 倍。
LMDeploy支持2种推理引擎: TurboMind和PyTorch,它们侧重不同,前者追求性能的极致优化,后者纯用python开发,着重降低开发者门槛。在实际部署时,首选TurboMind。
2.3 量化
两个基本概念
- 计算密集(compute-bound): 推理的绝大部分时间消耗在数值计算上;针对计算密集场景,可以通过使用更快的硬件计算单元来提升计算速度,比如量化为W8A8使用INT8 Tensor Core来加速计算。
访存密集(memory-bound): 推理时,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般是通过提高计算访存比来提升性能。
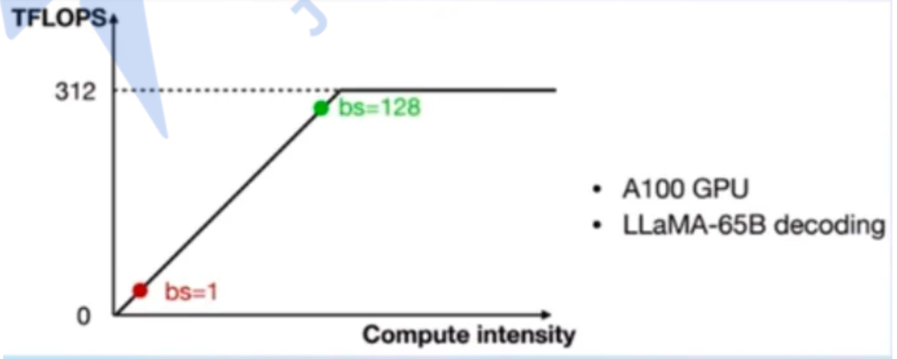
LLM是典型的访存密集型任务,常见的LLM模型是Decode Only结构,推理时大部分时间消耗在逐Token生成阶段(Decoding阶段),时典型的访存密集型场景。可以通过roofline模型来判断时计算密集型还是访存密集型。
如图: 可以看到只有在Batch Size 达到这个量级时,计算才会成为推理的瓶颈,但由于LLM模型本身就很大,推理时的KV-cache也会占用很多显存,还有一些其他的因素影响(如Persistent Batch), 实际推理时很难做到batchSize=128这么大,所以一般LLM服务都是访存密集型。
Weight Only量化一举多得
4 bit Weight Only量化,将FP16的模型权重量化为NT4, 访存量直接降为FP16模型的1/4,大幅降低了访存成本,提升了Decoding的速度。
加速的同时还节省了显存,同样的设备能够支持更大的模型以及更长的对话长度。
2.4 如何做Weight Only的量化
LMDeploy使用MIT HAN LAB 开源的AWQ算法,量化为4bit模型,推理时,先把4bit反量化回FP16(在Kernel内部进行,从Global Memory读取时仍时4bit),使用的是FP16计算。这样会造成一定的精度损失,但比直接用INT4计算准确。
2.5 推理引擎TurboMind
- continue batching:
- 请求可以及时加入batch中推理。
- Batch中已经完成的推理请求及时退出。
- 有状态推理
- 无状态推理: 每次请求均携带历史对话记录
- 有状态推理: 请求不带历史记录,历史记录在推理侧缓存。
- LMDeploy使用有状态推理,推理侧缓存历史对话的kv-cache。
- Blocked kv-cache
- Attention支持不连续的kv-cache
- block(Page attention)
三.LMDeploy量化部署
3.1 对量化前的模型做部署验证
模型下载参考大模型应用系列(二) Huggingface的安装和使用 | 乌漆嘛黑
这里以量化qwen2.5-7B为例,从模型的config.json文件可知,模型的权重被存储为bfloat16格式,对于一个7B(70亿)参数的模型,每个参数使用FP16表示(2个Byte),则模型的权重大小约为:
$70\times 10^9 parameters\times 2 Bytes /parameter=14GB$
所以需要大于14GB的显存。
3.2 创建环境
可以参考 大模型应用系列(六) ollama,vllm,LMDeploy 部署大模型 | 乌漆嘛黑
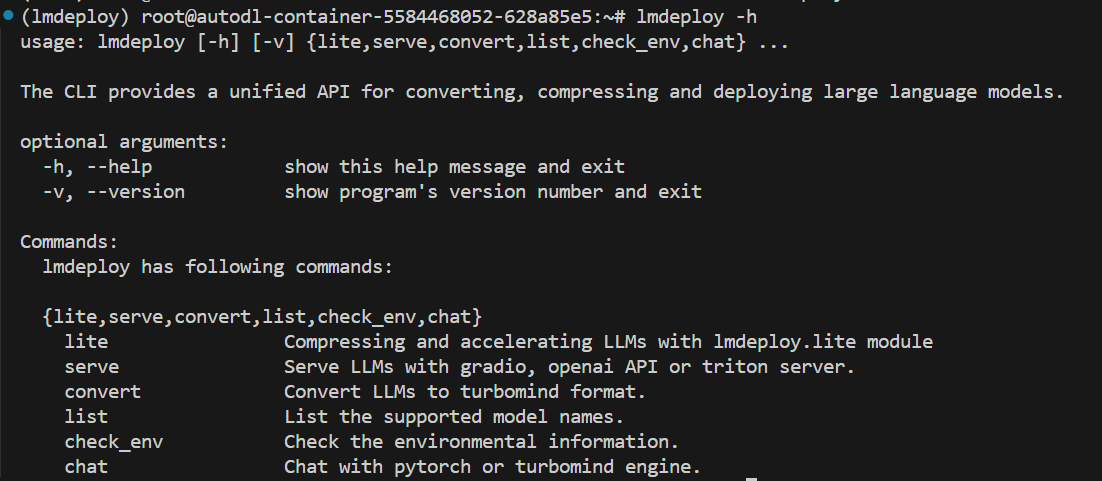
如果想要查看lmdeploy的具体命令,可以用以下命令
1 | lmdeploy -h |
可以看到lmdeploy支持以下几个子命令
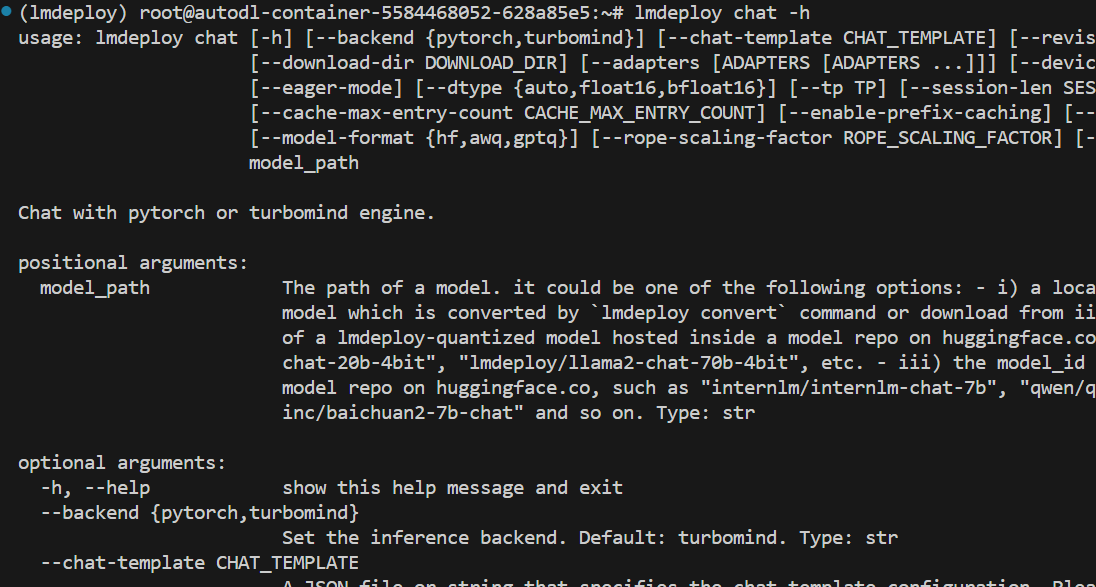
输入子命令查看指令可进一步查看子命令参数
1 | lmdeploy chat -h |
接着使用LMdeploy验证模型,进入创建好的环境并启动模型
1 | lmdeploy chat /root/autodl-tmp/Qwen2.5-7B-Instruct |
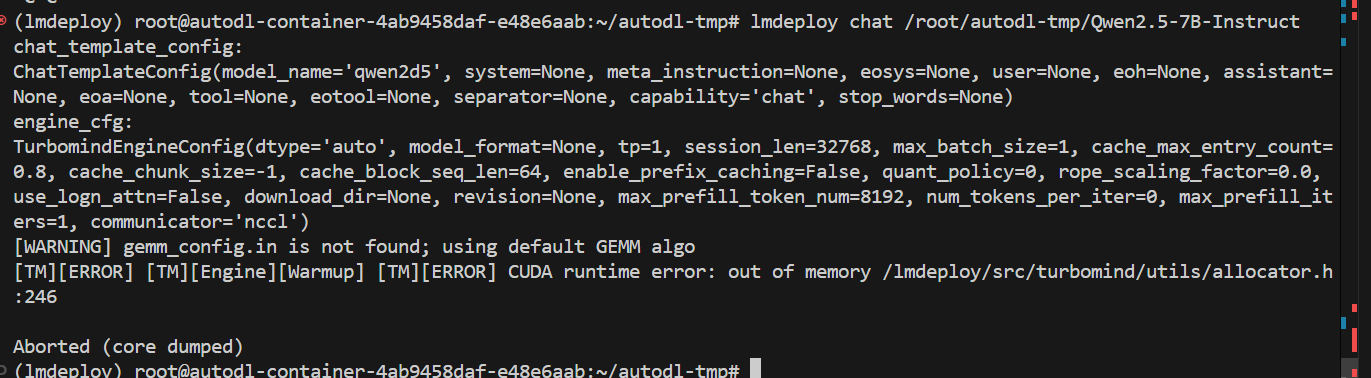
报错oom了,我的显存是24GB,上面计算模型需要14GB,模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy的kv cache管理器可以通过设置 控制kv缓存占用剩余显存的最大比例。默认的比例为0.8 。我们可以通过--cache-max-entry-count指定kv-cache的最大比例,比如设置为0.4:
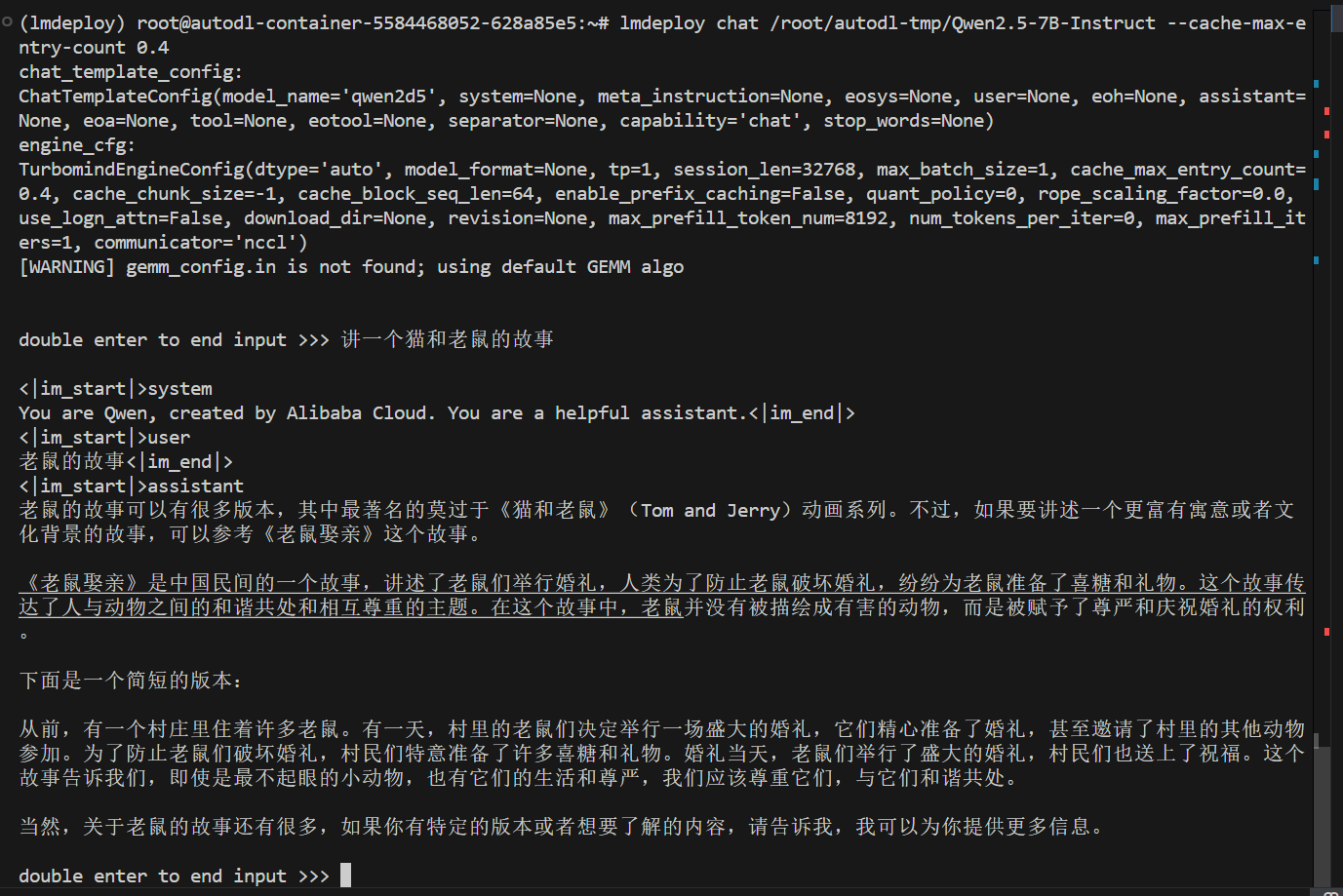
1 | lmdeploy chat /root/autodl-tmp/Qwen2.5-7B-Instruct --cache-max-entry-count 0.4 |
此时就可以正常启动了。
3.3 LMDeploy量化部署
3.3.1 lmdeploy 部署
使用以下命令
1 | lmdeploy serve api_server /root/autodl-tmp/Qwen2.5-7B-Instruct --model-format hf --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 1 --cache-max-entry-count 0.4 |
对命令的各个参数解释如下,也可以通过lmdeploy serve api_server -h 查看说明
1 | lmdeploy serve api_server:这个命令用于启动API服务器。 |
接着以命令行形式连接API服务器,以脚本形式连接在之前的openai兼容形式连接已经介绍过。
1 | lmdeploy serve api_client http://localhost:23333 |
3.3.2 LMDeploy Lite
随着模型变得越来越大,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。LMDeploy 提供了权重量化和 kv -cache两种策略。
部署时管理kv-cache主要有两个方式: 指定分配给kv-cache的内存大小(--cache-max-entry-count), 以及kv-cache量化策略(--quant-policy) , 自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 和 cache-max-entrycount 参数。目前,LMDeploy 规定 qant_policy=4 表示 kv int4 量化, quant_policy=8 表示 kv int8量化。
可以通过以下命令使用kv-cache量化
1 | lmdeploy serve api_server /root/autodl-tmp/Qwen2.5-7B-Instruct --model-format hf --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 1 --cache-max-entry-count 0.4 |
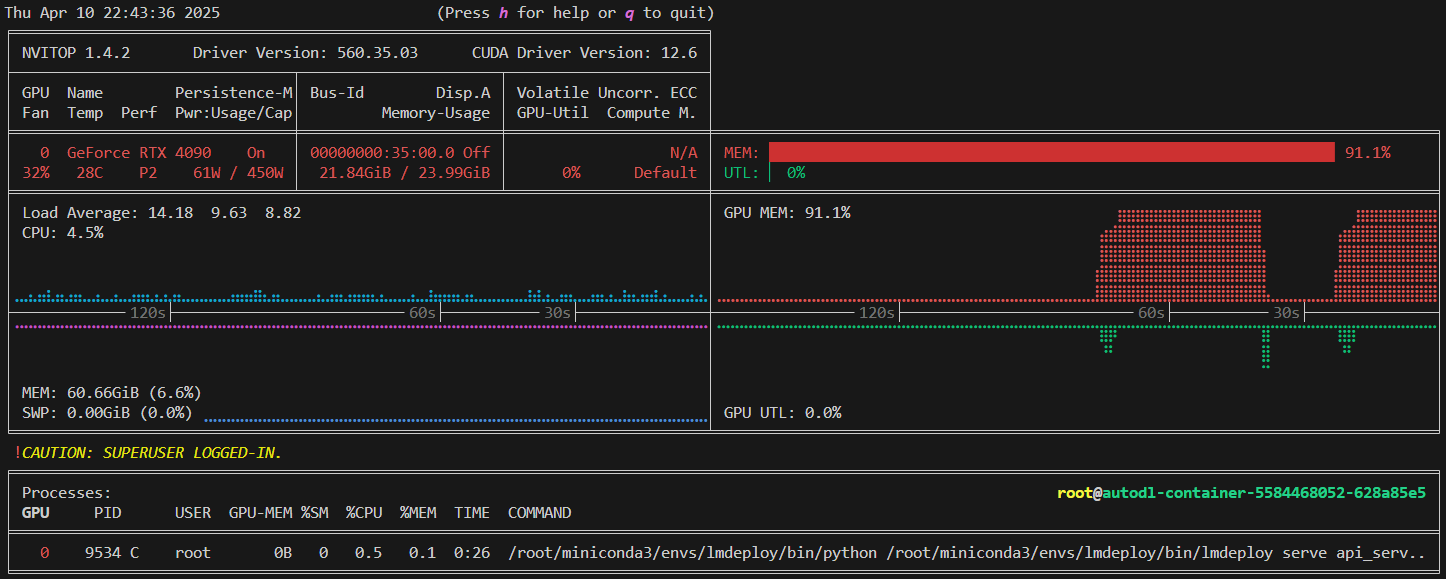
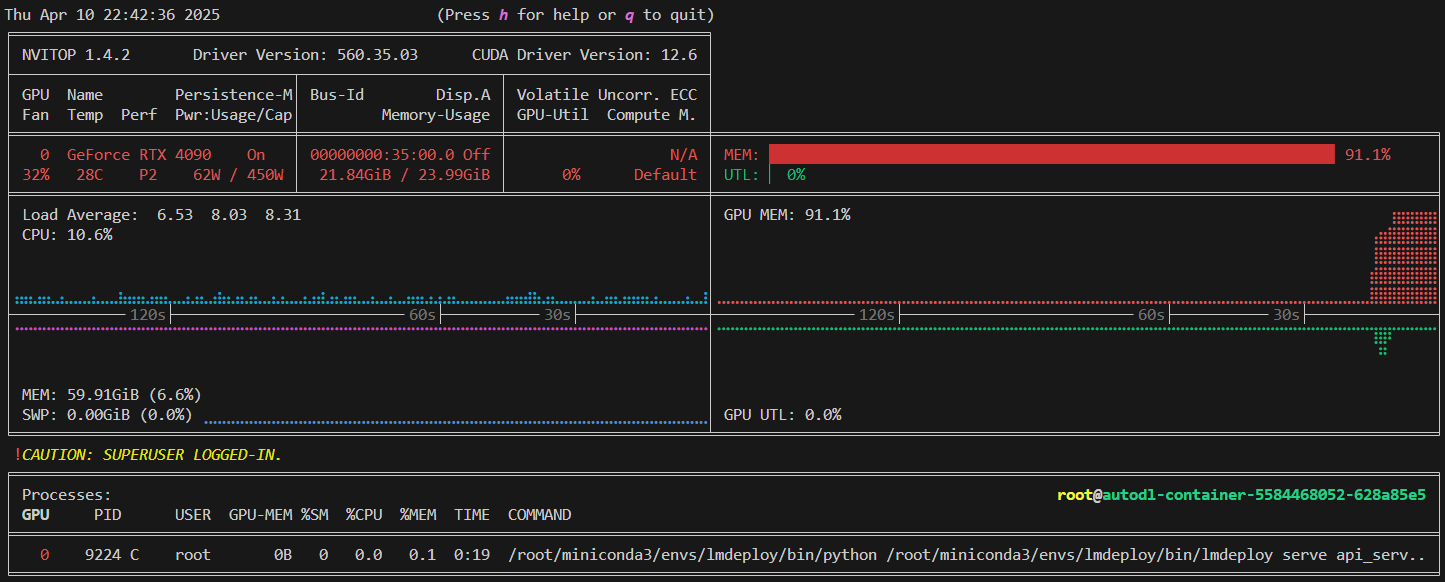
可以看出,量化与不量化的显存占用时相同的,这是因为kv-cache在命令中指定了显存比例,不论是否量化都会预分配那么多,但是如果测试就可以体会到,量化后可以输入更长的文本
| 不量化 | INT4量化 | INT8量化 |
|---|---|---|
 |
 |
 |
3.3.3 W4A16模型量化部署
模型量化旨在减少模型大小并提高推理速度,同时留出更多显存给kv-cache,能支持更长的prompt。量化通过将模型参数的权重和激活从高精度(比如FP16)量化为低精度(INT4,INT8),LMDeploy模型量化使用的是W4A16:
- W4: 表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16)转换为4位的整数表示。这样做可以显著减少模型的大小。
- A16: 这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
因此W4A16意味着权重(Weight)被量化为INT4,激活(Activation)保持FP16。
使用如下命令进行W4A16量化
1 | lmdeploy lite auto_awq /root/autodl-tmp/Qwen2.5-7B-Instruct --calib-dataset 'ptb' --calib-samples 128 --calib-seqlen 2048 --w-bits 4 --w-group-size 128 --batch-size 1 --work-dir /root/autodl-tmp/Qwen2.5-7B-Instruct-W4A16 |
命令参数解释如下:也可以通过lmdeploy lite auto_awq -h命令查看
1 | lmdeploy lite auto_awq: lite这是LMDeploy的命令,用于启动量化过程,而auto_awq代表自动权重 |
量化过程中要下载校准数据集,校准数据集在huggface上,如果访问不了外网会报错,需要在服务器上安装梯子,如果没有,可以用一种麻烦的方法,见4.1
解决了以上问题,就可以开始量化,量化过程会花一些时间,要等一等。
结束后进入目录/root/autodl-tmp使用如下命令查看文件及其大小:
du -sh * 显示如下:

可以看到量化后的模型比原模型大小小了很多。量化后的模型可以和原模型一样使用
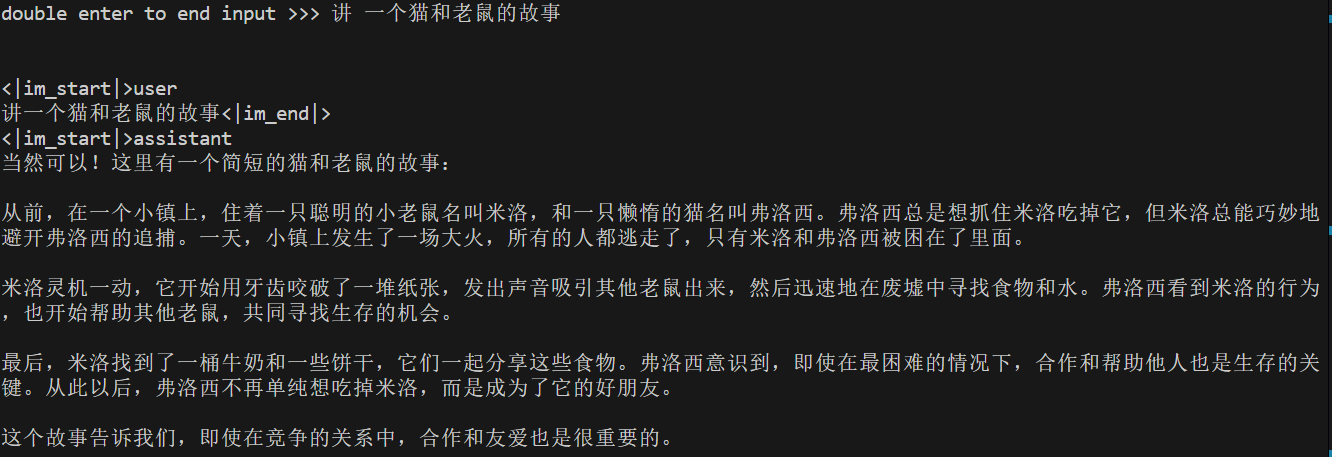
1 | lmdeploy chat /root/autodl-tmp/Qwen2.5-7B-Instruct-W4A16 --model-format awq |
3.3.4 离线转换TurboMind格式
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式,如下所示。
1 | lmdeploy convert Qwen2.5-7B-Instruct /root/autodl-tmp/Qwen2.5-7B-Instruct |
第一个参数是模型名称,用于选择对话模板。第二个参数是模型路径。
执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。 里面的参数文件如下:
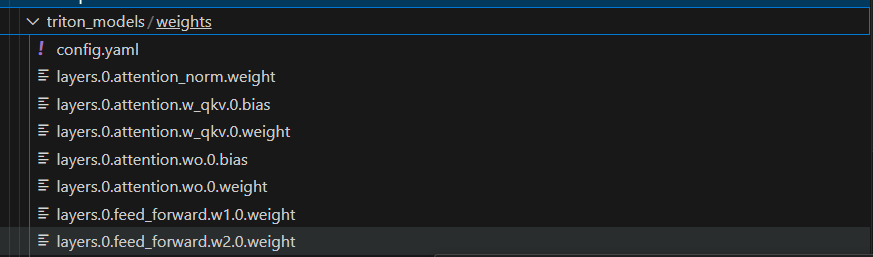
每一份参数第一个 0 表示“层”的索引,后面的那个0表示 Tensor 并行的索引,因为我们只有一张卡,所以被拆分成 1 份。如果有两张卡可以用来推理,则会生成0和1两份,也就是说,会把同一个参数拆成两份。比如 layers.0.attention.w_qkv.0.weight 会变成 layers.0.attention.w_qkv.0.weight和 layers.0.attention.w_qkv.1.weight。执行 lmdeploy convert 命令时,可以通过 --tp指定(tp 表示 tensor parallel,该参数默认值为1也就是一张卡) 。
转化为TurboMind格式后,就可以正常启动命令行本地对话了。
1 | lmdeploy chat /root/autodl-tmp/workspace |
启动后就可以和它进行对话了。
3.4 网页Demo演示
这里用Gradio作为前端Demo
先启动服务器,可以用上面的任一方式。这里用kv-cache量化部署方式,
1 | lmdeploy serve api_server /root/autodl-tmp/workspace --model-format hf --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 1 --cache-max-entry-count 0.4 |
接着在另一个终端启动Gradio, 如果报错缺少包,就pip缺啥装啥。
1 | Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client |
效果如下:
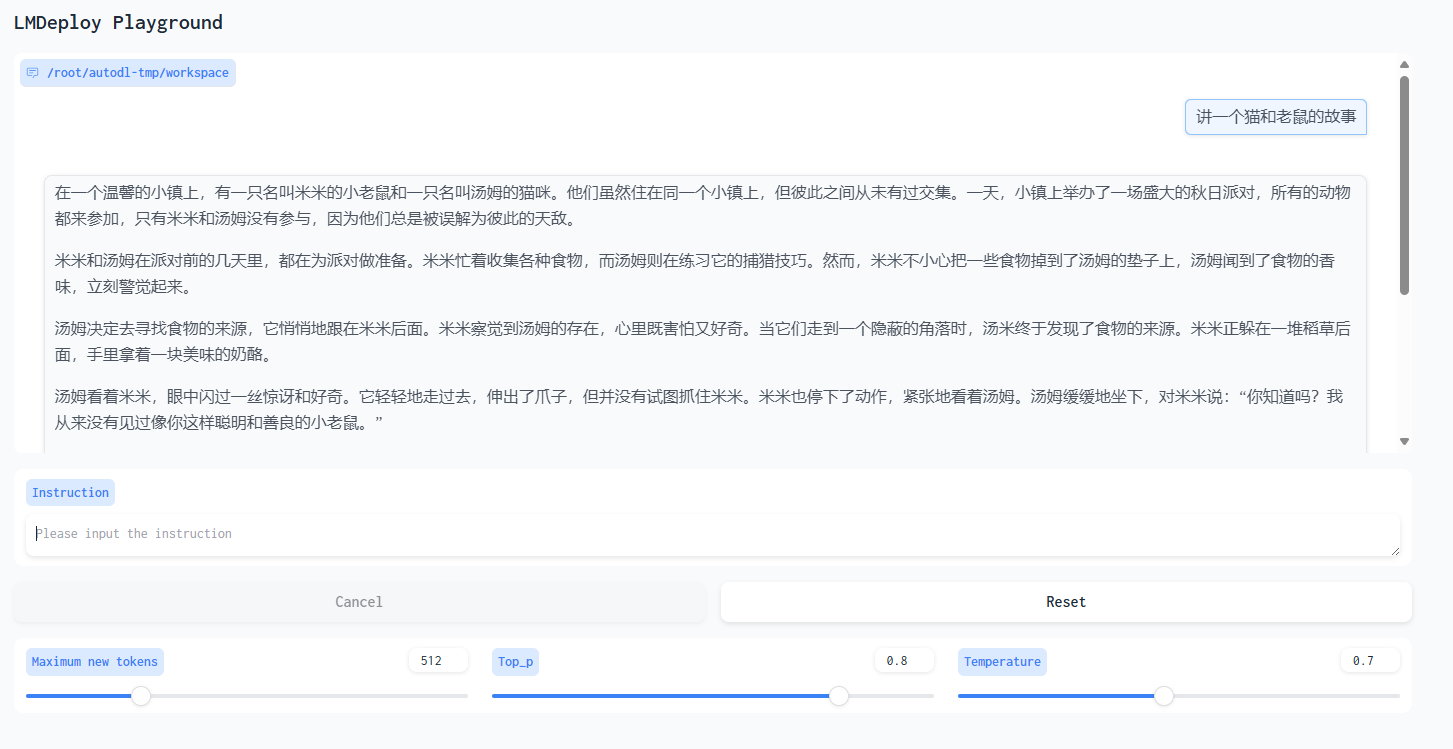
四. 补充
4.1 LMDeploy 模型量化时报错
在 3.3.3 中可能会报错,TypeError: 'NoneType' object is not callable , 原因是datasets 3.0 无法下载数据集``

将下载datasets的其他版本即可。运行下列指令
1 | pip install datasets==2.19.2 |
如果服务器上没有梯子,下载数据集时还会报错ConnectionError: Couldn't reach https://raw.githubusercontent.com/wojzaremba/lstm/master/data/ptb.train.txt (error 429)
可以先在本地翻墙把文件下载下来,使用如下代码
1 | from datasets import load_dataset |
下载的文件缓存在C:\Users\用户名\.cache\huggingface\datasets中,把里面的ptb_text_only 上传到服务器的~/.cache/huggingface/datasets 目录下即可,其他huggingface下载的数据集都可以通过这种方式解决。服务器上查询隐藏文件可以用ls --all。
