介绍DeepSeep框架,使用LLamaFactory和XTuner进行分布式微调。同时介绍XTuner的安装和使用,以及XTuner如何进行模型转换与合并。
一. 大模型分布式训练微调的基本概念
1.1 为什么需要分布式训练
- 模型规模爆炸: 现代大模型(如GPT-3、 LLaMA等) 参数量达千亿级别, 单卡GPU无法存储完整模型。
- 计算资源需求: 训练大模型需要海量计算(如GPT-3需数万GPU小时) , 分布式训练可加速训练过程。
- 内存瓶颈: 单卡显存不足以容纳大模型参数、 梯度及优化器状态。
1.2 大模型分布式训练的基本概念
1.2.1 分布式训练的核心技术
- 数据并行
原理:将数据划分为多个批次,分发到不同的设备,每个设备拥有完整的模型副本。
同步方式: 通过All-Reduce操作同步梯度。
挑战:通信开销大,显存占用高(需存储完整模型参数和优化器状态)
- 模型并行
原理:将模型切分到不同设备(如按层或张量分片)。
类型:
横向并行(层拆分):将模型的层分配到不同设备。
纵向并行(张量拆分):如Megatron-LM将矩阵乘法分片。
挑战:设备间通信频繁,负载均衡需要精细设计。
- 流水线并行
原理:将模型按层划分为多个阶段(stage),数据分块后按流水线执行。
优化:微批次(Micro-batching)减少流水线气泡(Bubble)。
挑战:需平衡阶段划分,避免资源闲置。
- 混合并行(3D并行)
组合策略,结合数据并行,模型并行,流水线并行,典型应用如训练千亿级模型。
案例:微软Turing-NLG, Meta 的LLaMA-2。
二. DeepSpeed框架介绍
2.1 DeeepSeep概述
定位:微软开源的分布式训练优化框架,支持千亿参数模型训练。
核心目标:减低大模型训练成本,提升显存和计算效率。
集成生态:与PyTorch无缝兼容,支持Hugging Face Transformer库。
2.2 核心技术
ZeRO(Zero Redundancy Optimizer) 优化器 ,具体参考模型显存占用计算以及Zero优化器 | 乌漆嘛黑
原理:通过分片优化器状态,模型梯度,模型参数,消除数据并行中的显存冗余。
阶段划分:
ZeRO-1:优化器状态分片。
ZeRO-2:优化器状态分片+梯度分片。
ZeRO-3:优化器状态分片+梯度分片+参数分片。
优势:显存随设备数线性下降,支持训练更大模型。
2.3 其他技术
梯度检查点(Activation Checkpointing):用时间换空间,减少激活值显存占用。
CPU Offloading:将优化器状态和梯度卸载到CPU内存。
混合进度训练:FP16/BP16与动态损失缩放(Loss Scaling)。
2.4 其他特性
大规模推理支持: 模型并行推理(如 ZeRO-Inference)。
自适应通信优化: 自动选择最佳通信策略(如 All-Reduce vs All-Gather)。
2.5 优势与特点
显存效率高:ZeRO-3可将显存占用降低至1/设备数。
易用性强:通过少量代码修改即可应用(如DeepSeed配置JSON文件)
扩展性优秀:支持千卡集群训练。
2.6 使用场景
训练百亿/千亿参数模型(如GPT-3,Turing-NLG).
资源受限环境:单机多卡训练时通过Offloading扩展模型规模。
加速训练:通过ZeRO-2加速中等规模模型训练。
三. 使用LLamaFactory进行分布式微调
3.1 LLamaFactory 安装
参考大模型应用系列(七) LLama Factory和OpenWebui的安装和使用 | 乌漆嘛黑
另外还要安装deepspeed
1 | pip install deepspeed |
我的服务器配置是:
PyTorch 2.5.1
Python 3.12(ubuntu22.04)
CUDA 12.4
RTX 4090(24GB) * 2
CPU32 vCPU Intel(R) Xeon(R) Gold 6430
3.2 选择配置
其他配置和之前一样,主要是配置DeepSpeed参数,
3.2.1 Zero-1
如果选择none,那么两张卡上都会放置完整模型。none的时候不会用deepspeed,只是常规的数据并行.(用nvitop监控)
一般在分布式训练时,选择Zero-2比较好。即配置中DeepSpeed stage设置为2。
3.2.2 Zero-2

从nvitop上不能明显看出显存减少,但可以从训练速度上体验到Zero-2比zero-1快,并且这种差距会随着GPU性能的提高而扩大。
3.2.3 Zero-3+offload
要想把显存占用率降到最低,就要使用Zero-3同时开启offload
可以看到显存降低了很多,但训练速度明显变慢了,慢多少取决于显存和内存的通信效率。

注意: 一般在分布式训练时,都使用Zero-2。
3.3 多机多卡训练
以上时单机多卡分布式训练
LLama-Factory 也提供了多机多卡训练,但无法通过界面化配置,具体训练方式见官网分布训练 - LLaMA Factory
四. XTuner的安装和使用
官网:欢迎来到 XTuner 的中文文档 — XTuner 0.2.0rc0 文档
XTuner也是一个微调训练框架,它不支持界面化操作,但比LLamaFactory更灵活,速度也快一些。
4.1 XTuner的安装
官方提供了通过pip安装和源码安装两种方式,但我们在微调过程中经常要用到源码,所以推荐直接从源码安装。XTuner需要python3.10的环境。
1 | conda create -n xtuner python==3.10 -y # 创建环境 |
验证安装是否成功
1 | xtuner list-cfg |
4.2 使用XTuner进行微调
XTuner进行训练时需要写配置文件。首先,你微调的模型必须XTuner支持,源码中的xtuner/xtuner/config 目录下的所有文件名就是XTuner支持的模型
比如它就不支持qwen2.5
4.2.1 准备数据集
官网给出了XTuner微调支持的数据集格式,如下:
1 | [{ |
它也支持下面的格式,这其实是目前比较推荐的格式。
1 | [ |
所以要把我们的自定义数据集调整为上述格式,这里以ruozhiba数据集为例, 使用如下脚本转换, 我们转换为第二种
1 | import json |
在XTuner根目录新建数据文件夹data把数据集放到其中。
4.2.2 修改配置文件
创建微调训练相关的配置文件在左侧的文件列表,xtuner 的文件夹里,有两个文件,一个是含有full是用于做预训练的配置文件,一个是含有qlora,用于微调。
这里选择的文件为:
/root/autodl-tmp/xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_0_5b_chat/qwen1_5_0_5b_chat_qlora_alpaca_e3.py
复制一份放到根目录。
接下来修改配置文件,主要修改以下几部分:
1 | ######################## PART 1 |
4.2.3 单卡微调
再xtuner目录下使用如下命令开始微调, 产生的日志文件存放在/root/autodl-tmp/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3 目录下。
1 | xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py |
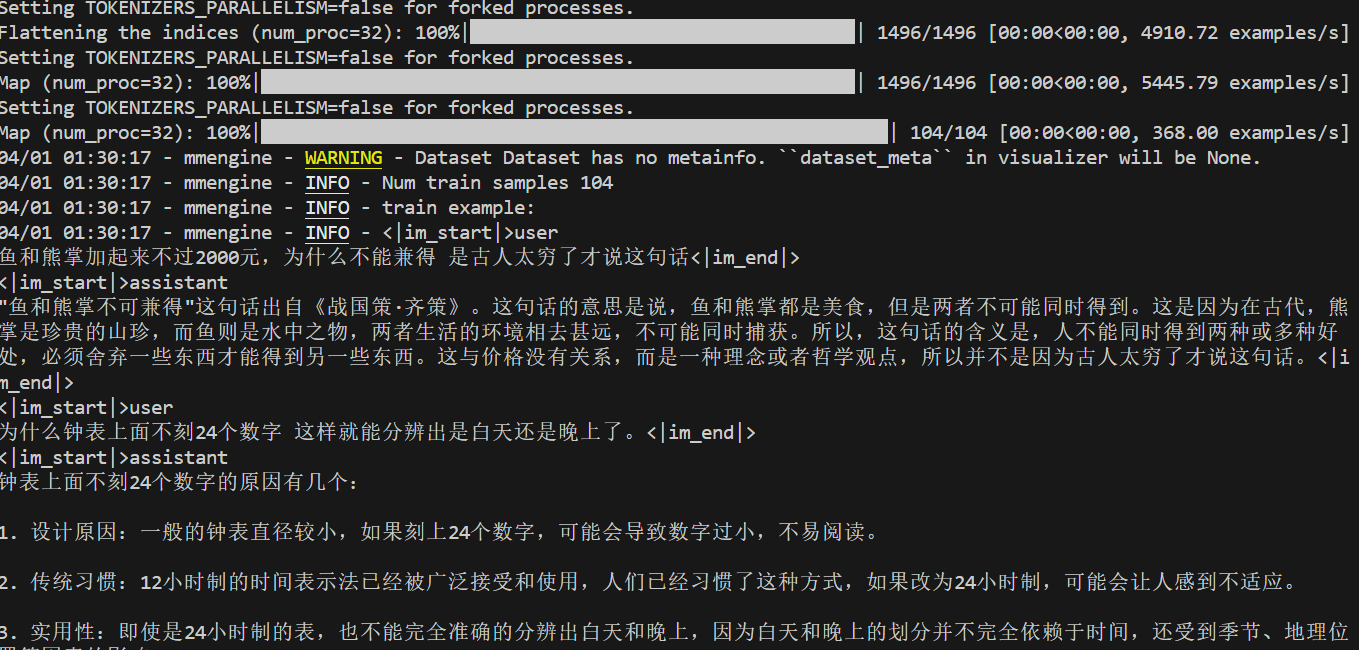
如果出现数据集处理,一般就是启动成功了。
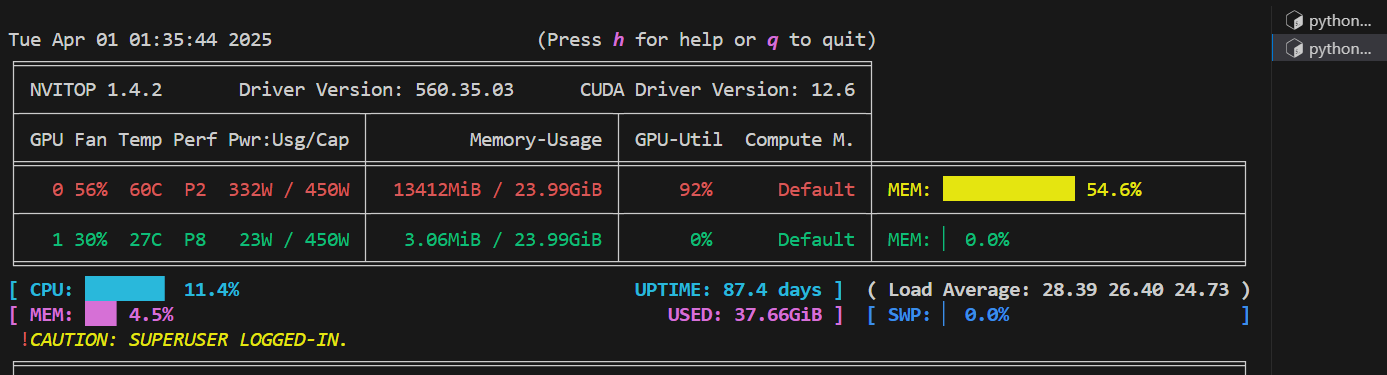
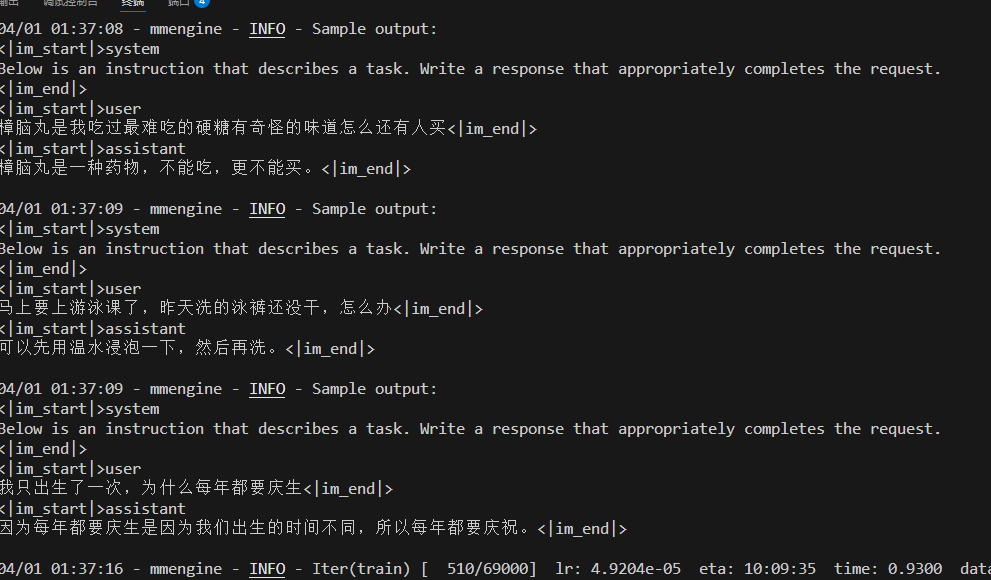
占用一张卡,同时从训练进度可以感受到,它比LLamaFactory快。
XTuner使用的是主观测试,所以固定轮次后会执行测试数据。
4.2.4 分布式训练
安装了DeepSpeed后,在执行命令之后加上DeepSpeed配置。
先指定GPU个数,如果是多级多卡还得指定节点数。后面加上deepspeed并指定Zerto等级
单机多卡:
1 | NPROC_PER_NODE=${GPU_NUM} xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2 |
比如我是单机双卡, 则指令为:
1 | NPROC_PER_NODE=2 xtuner train qwen1_5_0_5b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2 |
多机多卡:
1 | excuete on node 0 |
注: $PORT 表示通信端口、$NODE_0_ADDR 表示 node 0 的 IP 地址。 二者并不是系统自带的环境变量,需要根据实际情况,替换为实际使用的值。
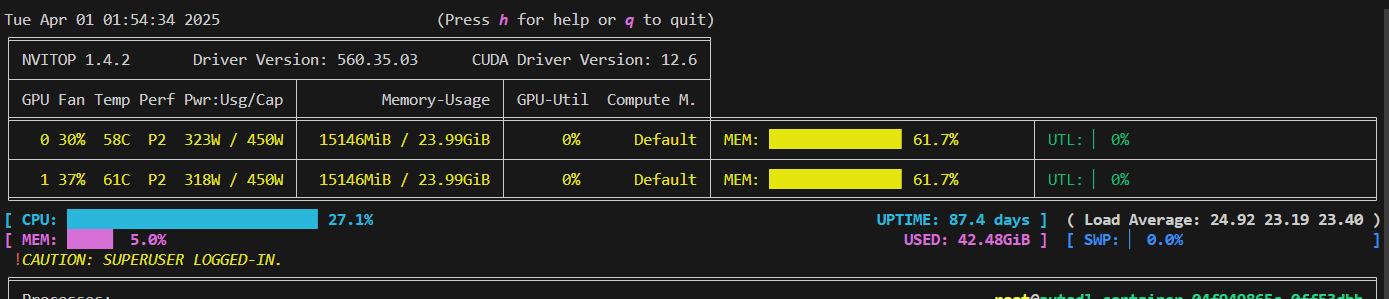
单机双卡GPU使用情况如下:可以看到两张卡都用了。
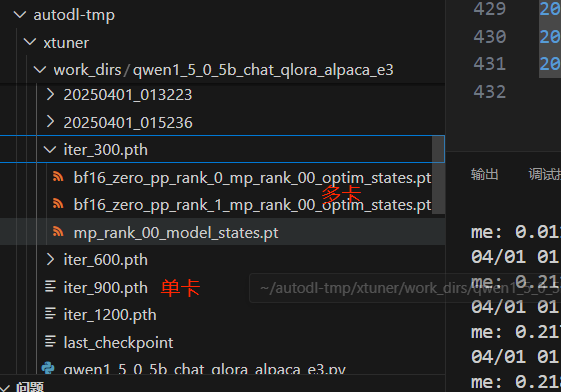
模型训练后会自动保存成 PTH 模型,保存在workdir中(例如 iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个文件夹,一张卡一个文件)
4.2.5 模型转换
微调后的LoRA是用pytorch保存的,无法直接合并,要先转为huggingface格式使用如下命令
1 | xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH} |
其中${FINETUNE_CFG} 为配置文件路径,${PTH_PATH} 为检查点路径,如果是单卡就是一个文件,如果是多卡就是文件夹,${SAVE_PATH} 是保存路径。比如我的命令如下:
1 | xtuner convert pth_to_hf /root/autodl-tmp/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/qwen1_5_0_5b_chat_qlora_alpaca_e3.py /root/autodl-tmp/xtuner/work_dirs/qwen1_5_0_5b_chat_qlora_alpaca_e3/iter_600.pth /root/autodl-tmp/hf |
运行后转换成功,
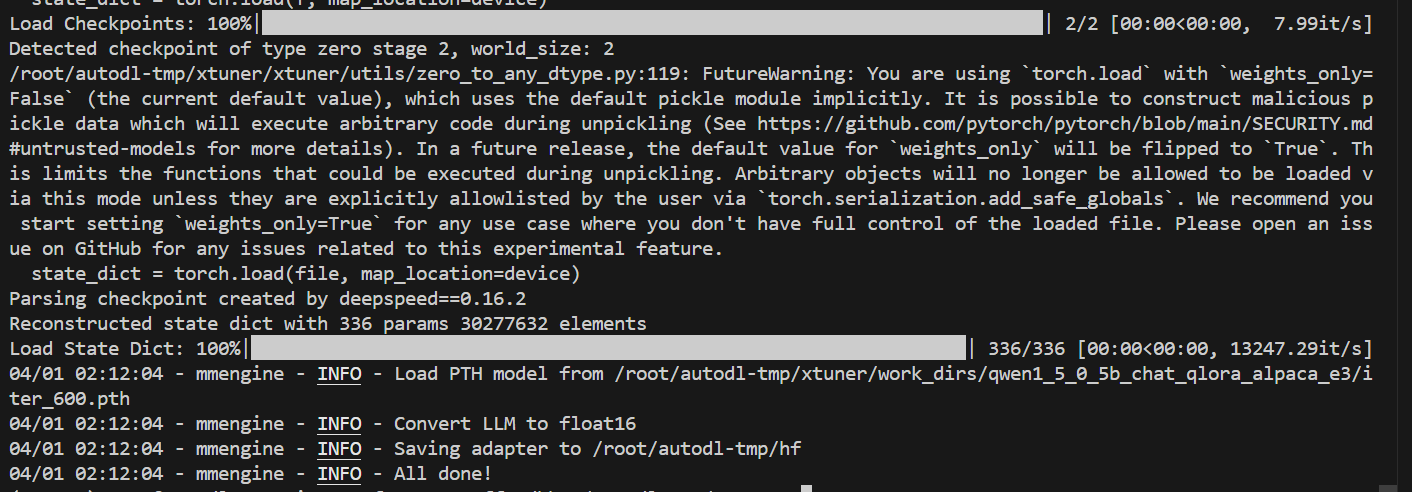
此时保存路径下会出现LoRA适配器参数。
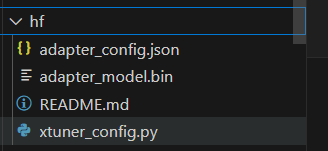
4.2.6 合并模型
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果你期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
1 | xtuner convert merge ${LLM} ${LLM_ADAPTER} ${SAVE_PATH} |
其中${LLM}是基座模型路径, ${LLM_ADAPTER} 是LoRA适配器路径 ${SAVE_PATH} 是模型保存路径。这里我命令如下:
1 | xtuner convert merge /root/autodl-tmp/Qwen1.5-0.5B-Chat /root/autodl-tmp/hf /root/autodl-tmp/Qwen2.5-0.5B-Chat-ruozhiba-600 |
执行后显示合并成功。

4.2.7 继续训练
在配置文件中指定加载检查点即可
1 | load from which checkpoint |
接着执行上述训练指令。可以看到,loss从一个较小的数开始,而不是一开始的2.几,说明模型是从检查点开始的。

五. 注意
5.1 显存释放问题
可能是AutoDL的问题,在使用LLamaFactory进行多卡训练时,点击 中断 后,只 会释放一个GPU的显存

解决办法是关闭llamafactory, 杀死运行的python进程。(使用top查看进程)
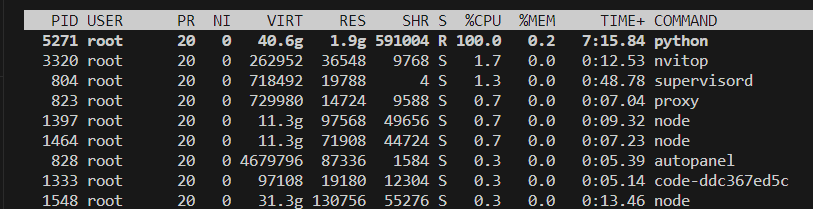
使用如下命令杀死进程
1 | kill 5271 |

5.2 数据集及配置
XTuner内置众多的 map_fn 开源指令微调数据集(LLM) — XTuner 0.2.0rc0 文档 ,可以满足大多数开源数据集的需要。此处我们罗列一些常用 map_fn 及其对应的原始字段和参考数据集:将数据集整理成对应的格式,然后再配置中指明对应的映射函数即可。

如果想要用其他对话模板,则需要额外的配置,比如LLamaFactory用的数据集格式为alpace,如果想用之前在LLamaFactory的数据集,则需进行额外配置。alpaca_map_fn如下:
1 | # Copyright (c) OpenMMLab. All rights reserved. |
可以看出,这个函数最终也是转换成4.2.1中的格式,这也是为什么4.2.2中不用额外指定映射函数的原因,因为我们已经把数据集整理成XTuner格式了,其他格式也是通过映射函数转化为XTuner格式的。alpcaca格式包含instruction,input,output三个字段,所以使用的弱智吧数据集格式如下:
1 | [ |
配置文件修改也有区别, 这里只给出不同的,其他的像4.2.2中修改即可
1 | ########## PART 1 |
通过以上配置,即可正常训练
5.3 XTuner 环境安装问题
报错 No module named ‘triton.ops’ 或者一直显示命令格式不对
这个是因为用了pytorch,将pytorch降到2.5.1可以解决, 首先修改/root/autodl-tmp/xtuner/requirements/runtime.txt 指定其中的pytorch版本
1 | torch==2.5.1 |
然后重新安装
1 | pip install -e '.[all]' # 安装 |
如果安装后还是一直报错,把虚拟环境删除,指定pytorch版本冲重新安装。
