介绍如何根据模型的参数量计算显存占用,介绍了分布式训练常见的通信原语,包括Reduce, Gather, Broadcast,Scatter,ReduceScatter,AllGather,AllReduce等,以及介绍Zero优化器三个级别各自的执行过程。
零冗余优化器(ZeRO)通过对三个模型状态(优化器状态、梯度和模型参数)进行划分而不是复制他们,消除了数据并行进程中的内存冗余。该方法与传统的数据并行相比,内存效率得到极大的提高,而计算粒度和通信效率得到了保留。
目前训练超大参数规模的模型仍然有许多显存方面的问题,目前常见的解决方案是数据并行(Data Parallelisms ,DP) 和模型并行(Model Parallelisms, MP)。基础的DP方法并不能降低每个GPU上的内存占用,因为他会拷贝模型。为了解决这个问题,有诸如流水线并行(Pipeline Parallelism, PP),MP或者借助CPU内存的方法,但这种方法都是以牺牲某些关键性能(如,内存,计算,通信开销)为代价。目前最有前景的方法是MP,即垂直地切分模型,将网络和参数切分到多个设备,需要每层之间进行大量的通信。
一. 优化前
ZeRO(Zero Redundancy Optimizer)的开发便是用于解决DP和MP的问题。在理解ZeRO的原理之前,需要深入了解DP、MP的问题:
● 内存为什么占用这么大
● 是参数所占的真实空间,还是存在冗余
● 可以如何优化
训练期间大部分的内存被模型状态(Model States)所消耗,包括优化器参数(Optimizer states), 梯度(Gradients) 和模型参数(Model Parameters)所消耗。除此之外,残余状态(Residual States)消耗了剩余的内存,包括前向传播是得到的Activateions,即时计算通信的临时穿冲区还有没有被妥善管理的内存碎片。将内存分为两部分: Model States和Residual进行讨论:
● Model States
混合精度训练和Adam优化器基本已经是训练语言模型的标配, 其中模型参数,模型梯度都是FP16,如果优化器是Adam,则还有FP32的一阶动量(momentum)和二阶动量(variance),混合精度训练同时存在FP16和FP32两种格式的数值,其中模型参数,模型梯度都是FP16,Adam的一阶动量和二阶动量是FP32,此外还有FP32的模型参数备份(backup)。(为什么要有FP32的模型参数备份?因为FP16累加误差会积累),假设模型参数规模为$\Phi$, 那么Model States的内存总开销为:
$Model States = Param + Gradient + Adam(momentum, variance) + backup = 2\Phi + 2\Phi + 2\times 4 \times \Phi + 4 \times \Phi = 16\Phi$
如果是1.5B的模型,$Model States=16\times 1.5B=24GB$, Model States远大于模型存储模型参数的显存,所以存在巨大优化空间。
● Residual States Memory
首先是激活值 Activations,Activation是在网络前向传播过程中每层神经元的计算结果,在反向传播时将结合梯度和这些激活值更新模型参数,所以需要保留这些Activation,常用的优化有:
Activation ChaeckPointing, 即只保存特定点的Activation,并在反向传播时重新计算没有保存的Activations, 这种方法代价是额外的计算时间,具体选择哪些点保存,一般是保存计算代价高但内存占用小的Activation,具体策略可以是固定或者启发式的。
Temporary buffers,一些操作如Gradient AllReduce或Gradient norm computation在使用高性能库时会尝试将所有参数融合到一个单一缓冲区以提高吞吐量,并且这些缓冲区的大小大多数情况下跟模型大小有关。(为啥这会影响内存开销?因为,当模型大小很大时,由于某些操作/高性能库的原因,会等待装填或者分配一个非常大的融合缓冲区去执行操作,这虽然会带来带宽和效率上的优势,但是有时却成为了内存瓶颈)
Memory Fragmentation, 如Activation原来存储在连续的空间,使用Activation checkpoint技术后释放一些激活值,这时其他激活值仍未释放,就会造成碎片化。
二. 分布式训练常见的通信原语
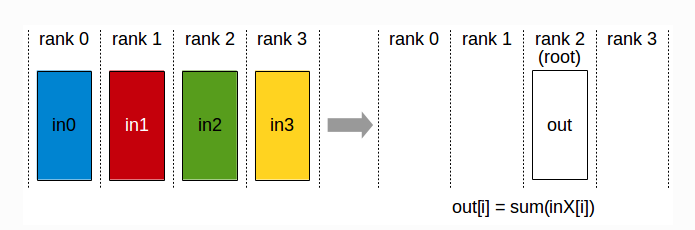
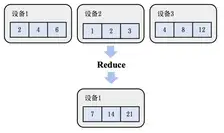
2.1 Reduce
reduce: 归约。属于多对一通信原语,多个数据发送者, 一个数据接收者。可以在集群内把多个节点的数据归约到一个节点上,如下图, 归约前每个节点有各自的数据,归约后接收节点有所有节点的数据的计算结果。常用于累加,累乘,求最值等操作。
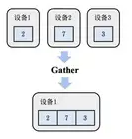
2.2 Gather
Gather:聚合。属于多对一通信,多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据聚合到一个节点上,聚合前每个节点拥有一份完整数据的一部分,聚合后接收节点拥有完整数据,Gather只是把所有多个节点的数据放到一个节点上,reduce会进行映射操作(求和,求最值等)。
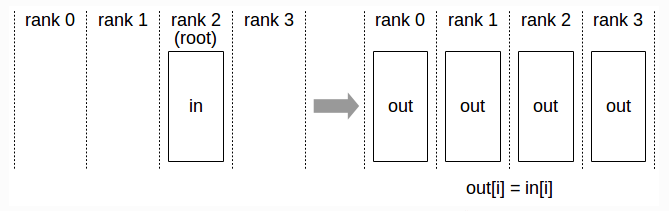
2.3 Broadcast
Broadcast: 广播。属于一对多通信原语,一个数据发送者,多个数据接收者。可以在集群内把一个节点的数据广播到其他节点上。广播后每个其他节点具有和发出节点相同的数据。
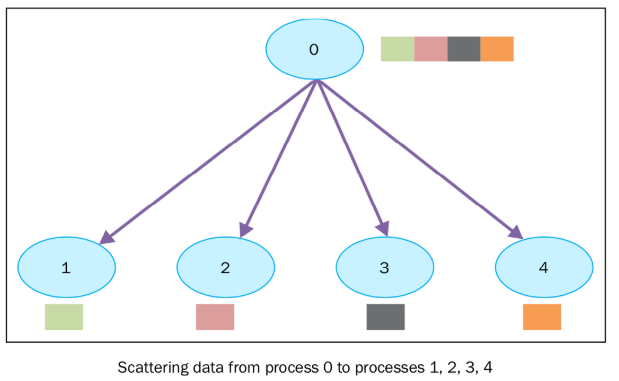
2.4 Scatter
Scatter:散开。属于一对多通信原语,一个数据发送者,多个数据接收者。可以在集群内把一个节点的数据发散到其他节点上,与Broadcast不同的是Scatter是先切分后发送,每个接收节点只收到发送节点的一部分数据(合起来是完整的)。
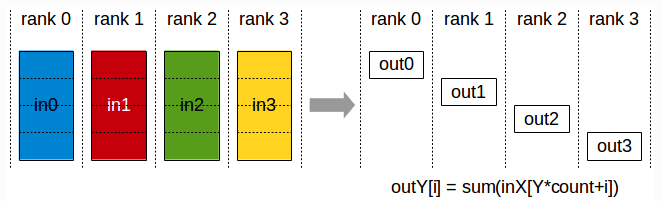
2.5 ReduceScatter
ReduceScatter: 属于多对多通信。多个数据发送者,多个数据接收者。先把所有节点的数据通过reduce归约到同个节点,再从这个节点发散到其他节点。最终每个节点都拥有归约后完整数据的一部分。
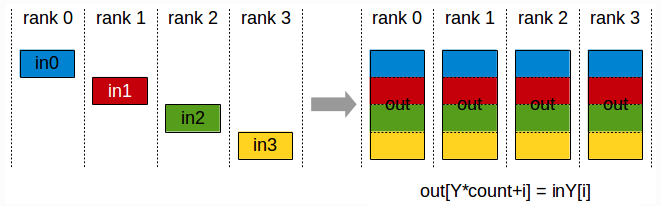
2.6 AllGather
AllGather: 属于多对多通信。多个数据发送者,多个数据接收者。发送前每个数据有完整数据的一部分,先通过Gather操作把所有数据聚合到一个节点上,再通过Broadcast(广播)发送到所有节点上,AllGather后每个节点都有一份完整数据。
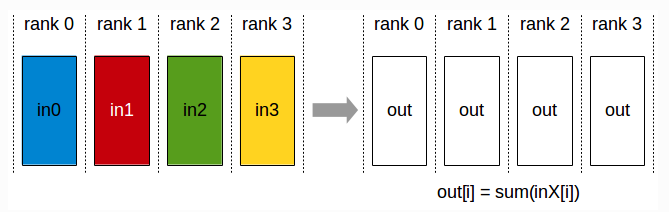
2.7 AllReduce
AllReduce: 属于多对多通信。多个数据发送者,多个数据接收者。发送前每个节点有一份完整数据的旧版本,先归约更新为新版本,再发送到每个节点上。AllReduce后每个节点都有完整数据的新版本。AllReduce可以通过在主节点上进行Reduce+Broadcast(先归约更新数据, 再广播数据)实现, 但这种方式主节点负责所有数据的聚合和广播,会成为性能瓶颈。也可以通过ReduceScatter+allGather(先归约更新,再发散,最后先聚合后广播),目前多用基于环的ReduceScatter和AllGather,高效实现AllReduce
三. Zero优化器
首先是将ModelStates (包含模型参数,梯度参数,优化器参数)划分到各个GPU上。
3.1 Zero-1
ZeRO-1: 对优化器参数进行划分,具体步骤如下(N个GPU):
- 把batch分成N份, 每个GPU一份
- 执行一步前向和方向传播计算后,每个GPU各得到一份梯度
- 对梯度执行all-reduce操作,所有节点都有一份完整梯度
- 每个GPU得到完整梯度G后,对各自的权重进行更新,权重的更新由优化器状态和梯度共同决定,每个GPU只需要存储和更新1/N的优化器状态,并更新1/N的权重(模型参数)。
每个GPU维护各自优化器里面更新的参数,最后执行all-gather,使得每个GPU都有更新后的权重。
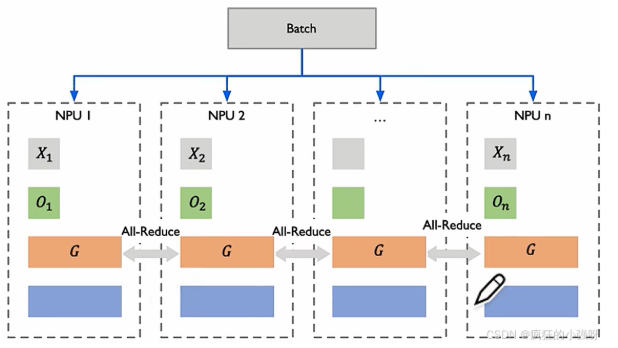
3.2 Zero-2
ZeRO-2: 对优化器和梯度进行划分,具体步骤如下:
- 把batch分成N份,每个GPU一份
- 执行一步前向和反向传播计算后,每个GPU得到一份梯度
- 对梯度执行all-reduce,所有节点都有一份完整梯度
- 聚合之后对梯度进行划分,比如GPU1只负责维护梯度G1,就只需要把G1的新梯度分为GPU1,其他的梯度就不需要保存。
- 每个GPU用所维护的优化器和梯度更新相应的权重,即每块GPU维护独立的权重。
最后对权重进行all-gather, 每个GPU都有完整的更新后的权重。
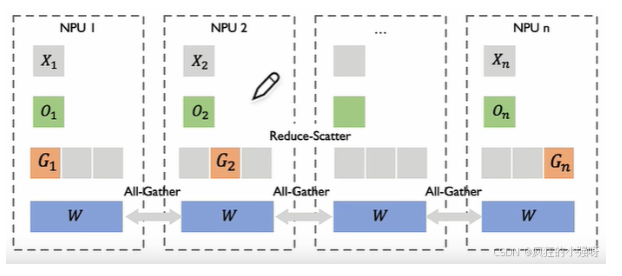
3.3 Zero-3
ZeRO-3: 对优化器,梯度,权重进行划分,具体步骤如下:
- 把batch分成N份,每个GPU一份,模型的权重参数也被分成N份。
- 在进行前向计算之前,对权重执行all-gather操作取回分布在各GPU上的权重,组成完整的参数进行前向计算,计算完成后,把不属于自身维护的权重抛弃。
- 在进行反向计算之前,对权重执行all-gather操作取回分布在各GPU上的权重,组成完整的参数进行反向传播计算,计算完成后,把不属于自身维护的权重抛弃。
- backward之后得到各自的梯度,对梯度执行all-gather操作,得到聚合的梯度之后更新自身维护的权重,然后把不是自身维护的权重抛弃。
由于每个GPU只保存其自身维护的权重参数,因此无需对权重进行all-reduce。
注: ZeRO-3是以通信换显存,ZeRO-3对权重参数进行了切分,但不是张量并行,因为在前向和反向计算时仍然用完整的权重来计算,张量并行在前向和反向时只用部分权重。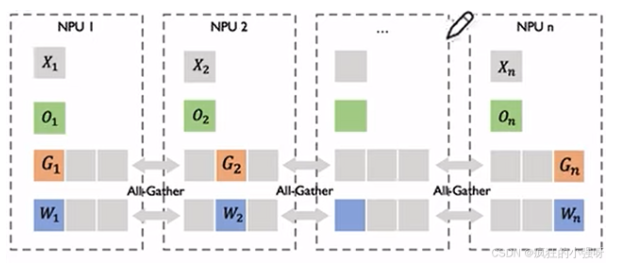
ZeRO-offload: 把显存占用多的部分卸载到CPU内存上,计算和激活值部分放到GPU上。
● 高计算: 前向传播和反向传播计算量高,相关权重参数计算和激活值计算仍然在GPU
● 低计算: 权重更新部分计算量低,以通信为主,且需要的显存大,放入CPU。
