解决在微调和部署时对话模板不统一的问题。
一. 发现问题
我们在大模型应用系列(七) LLama Factory和OpenWebui的安装和使用 | 乌漆嘛黑中学习了如何通过脚本或者LLama-Factory微调大模型,大模型应用系列(六) ollama,vllm,LMDeploy 部署大模型 | 乌漆嘛黑
中学习了如何使用Ollama, vllm, LMDeploy部署大模型,我们在使用的过程中就会发现,如果在LLamaFactory上微调到基本收敛了,此时在LLamaFactory上的对话框输出是正常的,符合预期的,但是使用其他部署工具部署的模型输出又不一样了。以下展示一些不同, 这里的模型是大模型应用系列(七) LLama Factory和OpenWebui的安装和使用 | 乌漆嘛黑训练的弱智吧对话AI,
1.1 LLamaFactory
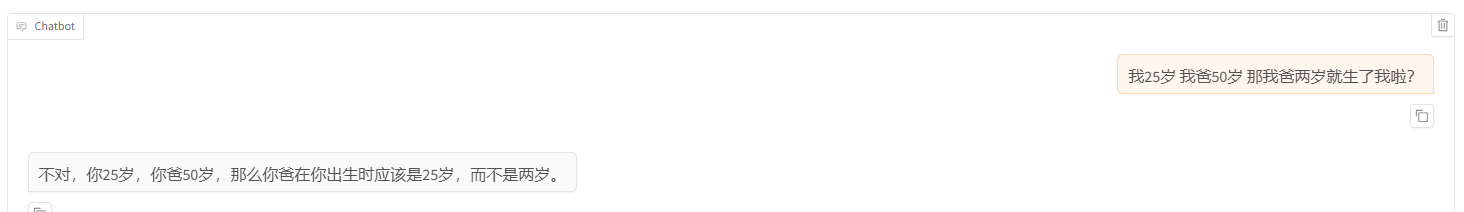
1.2 openWebui
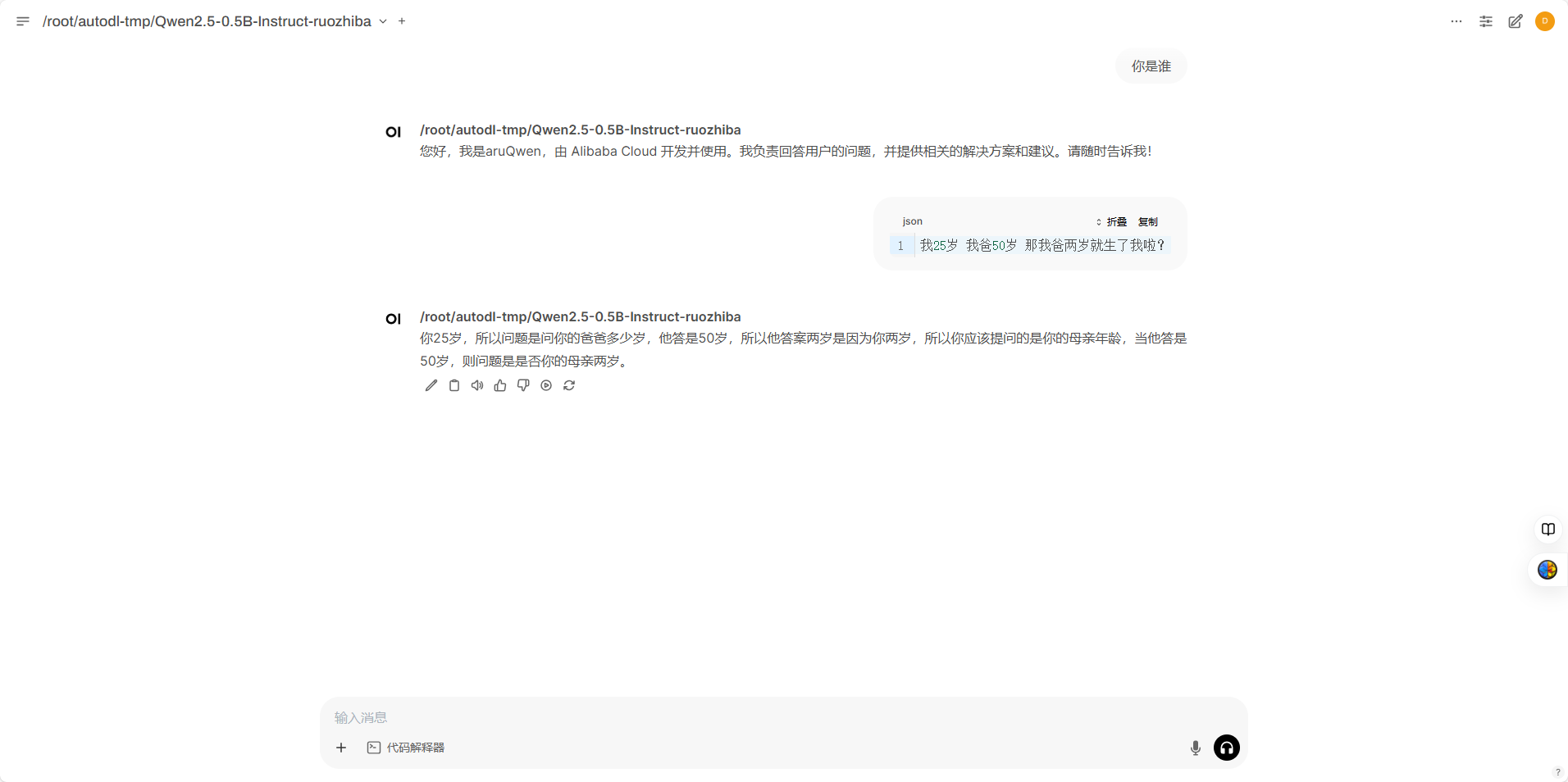
1.3 vllm
这里直接使用之前的vllm部署中多轮对话的代码

可以看出,模型的输出都有区别,其中LLamaFactory的输出最符合数据集(和数据集一样,因为训练loss基本不下降了)。
二. 分析
发生上述原因主要是不同的框架使用的对话模板不同,首先所有大模型的文件中存在模型自定义的对话模板,但是不同的大模型的对话模板是不同的,下面分析不同模型和框架的对话模板:
2.1 Qwen 对话模板
大模型自带的对话模板可以从它文件中的tokenizer_config.json中查看,比如qwen2.5的对话模板为:
1 | "chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n", |
同样,可以从qwen1.5的tokenizer_config.json文件中查看qwen1.5的对话模板
1 | "chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}", |
对比可以看出, qwen2.5和qwen1.5的对话模板是不一样的。同样,比如GPT的对话模板和Qwen更是不一样的,也就是说大模型的对话模板并没有统一标准,实际上也不能统一,因为不同大模型架构是不同的,qwen1.5和qwen2.5架构也是有区别的,所以对话模板也不同。但这样我们的输入都需要按对话模板转为后才输入到大模型,同样的输入经过不同的对话模板就会变得不同。
2.2 llamaFactory 对话模板
LLamaFactory中,我们在配置的时候,有个比较奇怪的地方,我们用的是自己的模型,按理来说只需要把模型路径传进去就行,为什么还要选择它的基座模型是什么。我们注意到选择不同系列的模型,变化的除了模型路径(可以使用我们自己的模型路径替换)还有对话模板。其实这个选项主要就是为了选择对话模板,也就是说LLamaFactory内置了很多对话模板,通过模型名称选择对应的对话模板,同时我们也注意到Qwen的qwen, qwen1.5,qwen2,qwen2.5系列对应的对话模板都是一样的。
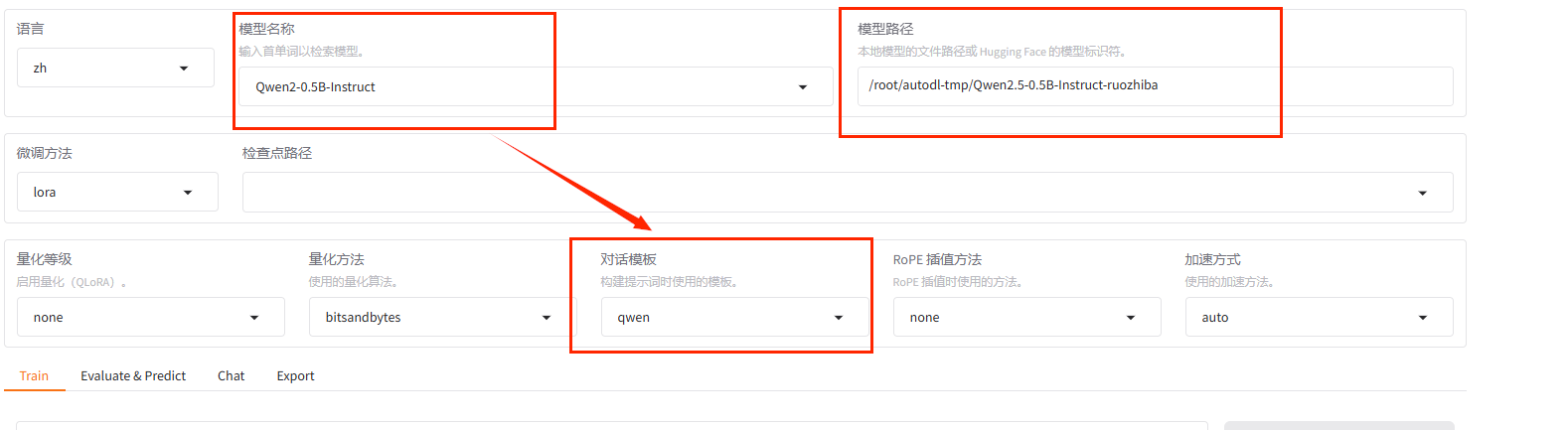
也就是说LLamaFactory的对话模板不是用大模型的模板,而是用自定义的模板。LLamaFactory的对话模板定义在在源码中的LLaMA-Factory/src/llamafactory/data/template.py文件中,比如Qwen的对话模板定义如下:
1 | # copied from chatml template |
所以当我们在前端选择的时候,就会注册一个对话模板,LLamaFactory的对话模板是参考官方的,但是还是不一样的,我们微调Qwen的时候,不管是qwen1.5还是qwen2.5,都是qwen的模板,微调完,我们用LLamaFactory的Chat功能,它也是用qwen的对话模板,这时候输出是正常的,但当我们使用vllm部署后,它默认使用的是模型自带的模板,就和我们微调时的模板不一样,就可能产生不一样的输出。
2.3 vllm对话模板
vllm对话模板的介绍可以从其官方文档中找到OpenAI 兼容服务器 | vLLM 中文站
文档中给出了自定义对话模板的办法,即通过--chat-template定义指明对话模板文件,对话模板的格式为Jinja2, 它是python的模板引擎,具体介绍可在其官网找到欢迎来到 Jinja2 — Jinja2 2.7 documentation
大部分大模型的对话模板都是用Jinjia2, 也有一些用json
2.3 OpenWebui对话模板
OpenWebui会覆盖掉我们定义的模板,并且没有提供自定义对话模板,所以还没找到解决办法。
三. 解决方案
3.1 统一LLamaFactory和vllm对话模板
做法:把vllm的对话模板替换为LLamaFactory的对话模板。
问题:为什么不把LLamaFactory的对话模板替换为模型自带模板?
解答:LLamaFactory把数据处理封装成服务,我们只需要按照LLama规定的格式(json),处理数据集,导入数据集后它后面还是会像之前微调Bert 大模型应用系列(三) Bert微调-评论情感分析 | 乌漆嘛黑那样封装成dataLoader,如果把对话模板改了,封装过程可能也得改变,就得改它的源码,是比较困难的 ,这也是LLamaFactory为什么qwen1.5和qwen2.5使用相同模板,因为如果每个系列的模型都用不同模板,那要定义很多封装过程,维护成本太高。vllm提供了修改对话模板的接口,我们目的是保持vllm和微调时对话模板一致,所以我们选择更改vllm对话模板。
具体做法:把2.2中的对话模板转化为Jinja2格式,启动vllm时传入参数。
通过阅读LLamaFactory源码,我发现它在文件LLaMA-Factory/src/llamafactory/data/template.py中提供了获取jinja2格式对话模板的函数。
这个方法的功能就是传入预训练模型的名称,返回jinja2格式的对话模板, 这个函数定义在类template中,但它私有化了,我们无法调用,
1 | def _get_jinja_template(self, tokenizer: "PreTrainedTokenizer") -> str: |
它也没有提供调用这个函数的接口,但是提供了另一个把tokenizer中的对话模板转为LLamaFactory定义的jinja2格式模板的方法:
1 | def fix_jinja_template(self, tokenizer: "PreTrainedTokenizer") -> None: |
我们可以先定义一个Tokenizer(随便定义都可以),获取template对象,然后传入到fix_jinja_template函数中获取对话模板。具体代码如下:
1 | # mytest.py |
把这个文件放在template.py的同级目录下。最后在同级目录下生成的chat_template.jinja文件即为LLamaFacotory的Qwen对话模板jinja格式。
接着在启动vllm时通过--chat-template 指定对话模板:
1 | vllm serve /root/autodl-tmp/Qwen2.5-0.5B-Instruct-ruozhiba --chat-template /root/autodl-tmp/LLaMA-Factory/src/llamafactory/data/chat_template.jinja |
通过指定对话模板,vllm输出和原先训练数据一致。

3.2 统一LMDeploy和LLamaFactory的对话模板
LMDeploy的对话模板是json格式,可以将上面得到的jinjia2格式转化为json格式,具体方法见官网自定义对话模板 — lmdeploy
这里我以使用Xtuner微调Qwen2.5-7B-Chat, 并且用LMDeploy部署为例。
在使用Xtuner微调时,需要修改配置文件,配置文件中指定了对话模板:
1 | prompt_template = PROMPT_TEMPLATE.qwen_chat |
然后到xtuner/xtuner/utils/templates.py 找到qwen_chat模板:
1 | qwen_chat=dict( |
我们要将上述模板转化为json格式,可以用AI生成一个脚本即可(在官网找到目标模板,告诉AI现在模板和目标模板),生成如下脚本,根据对话模板不同需要调整,主要调整到和官方示例一致就行:
1 | import re |
运行后会生成json文件,在LMDeploy部署时选择对话模板即可
1 | lmdeploy serve api_server internlm/internlm2_5-7b-chat --chat-template ${JSON_FILE} --server-port 8000 |
部署成功后另起终端运行下面推理代码:
1 | from openai import OpenAI |
运行后正常输出:

四. 补充
微调时用LLamFactory的模板会导致模型变差吗?
不会,模板只改变输出格式,不改变模型能力,我们微调时使用LLamaFactory的chat方法测试,证明在这种模板下已经获得预期效果了,所以我们部署是要做到是还原模型的效果,所以部署工具用LLamaFactoryd 对话模板。
