LoRA与QLoRA的异同,以及如何在LLamaFactory上使用LoRA与QLoRA
一. 补充
LoRA 和 QLoRA
LoRA: LoRA是一种用于微调大模型的技术,通过低秩近似分解方法适配数十亿参数到特定领域。
QLoRA: QLoRA是一种高效的大模型微调方法,显著降低了显存使用量,同时保持了bf16微调的性能。它通过一个固定的,4位量化的预训练语言模型进行反向传播梯度到低秩适配器来实现这一目标。
大模型的大指的是参数量大,在微调过程中,我们可以采用降低模型参数精度来节约显存,以此来增大batch_size加快训练。
问题:模型的量化是以牺牲模型精度为代价的,训练过程中使用量化不会降低模型的精度,因为训练过程中参数还没有确定,AI训练的结果不是准确的值,而是数据分布,模型之所以可以量化,是因为量化后虽然参数绝对值变化了,但他们拟合的分布不变。
注意: 在量化微调中,量化只发生在内部训练过程,并不影响模型最终的数据类型,模型原有参数类型在量化微调训练中会量化,但参数保存时又会恢复,因此量化微调并不影响模型本身的参数类型。
微调的目标
微调的理想目标是让模型在测试数据集上达到拟合状态(损失收敛), 根据测试集损失或者精度来表达,生成模型通过客观评价并不可靠。
模型微调多少个epoch才会拟合
一般3-5个epoch就会其效果,但多少个epoch拟合是未知的,模型拟合和两个因素有关:模型的复杂程度和数据集的复杂程度,一般来说,模型越复杂,数据集越复杂,需要的epoch越多。在具体实验中,一般会给一个较大的epoch(比如几千),主要防止模型未达到拟合训练就结束了(因为训练过程人不会一直看着)。
一般训练到损失收敛就可以了(loss不怎么下降了)
二. LLama-Factory的安装
我的服务器配置为:
RTX 4090, cuda 12.4 python=3.10 pytorch=2.5.1
参考:大模型应用系列(七) LLama Factory和OpenWebui的安装和使用 | 乌漆嘛黑
三. 准备模型和数据集
使用的是多轮数据集,法律相关,可以从下面链接下载:
将数据集上传到data文件夹中,并在dataset_info.json中添加数据集文件信息:
1 | "fintech": { |
模型下载可以参考: 大模型应用系列(二) Huggingface的安装和使用 | 乌漆嘛黑
这里选择的模型是Qwen2.5-1.5B-Instruct
四. 进行QLoRA微调
启动LLamaFatory
1 | cd LLaMA-Factory |
设置参数:要注意QLoRA的量化等级,指的是在训练过程中模型的量化等级,量化等级越高模型精度越低,跟模型大小也有关,如果模型很大,那量化等级可以开高一点。这里才1.5B,所以只开了INT8
开启QLoRA之后,还要调整LoRA参数,通过大量实验得出,QLoRA中LoRA的秩最低要32,最好是60左右,(一般是32到128之间)如果模型比较大,那可以小一点,但如果模型很小,LoRA的秩就要大一些。另外LoRA缩放系数一般设为LoRA的秩的两倍。LoRA秩越大,显存占用越大。

配置好后点击启动开始QLoRA微调,一开始loss反而上升是正常现象,一般五次后能下降就是正常的。
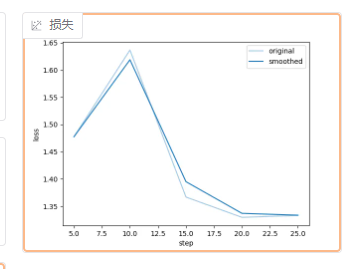
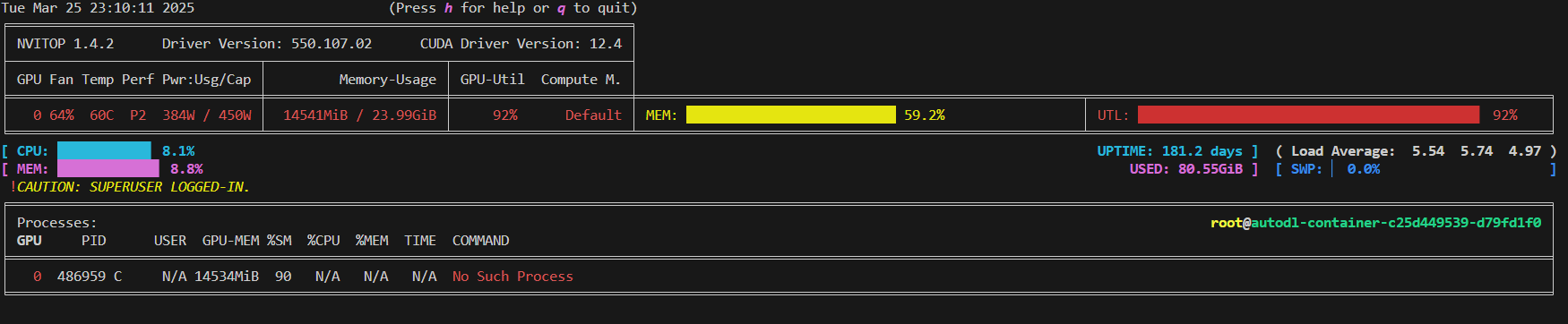
这里显存利用率还没到90%, 说明batch_size还可以加大。
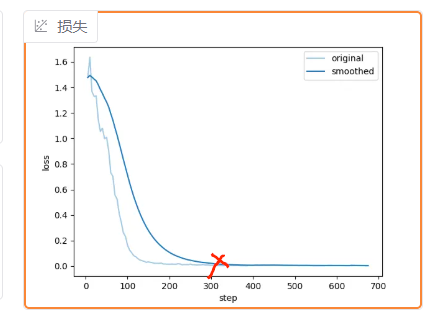
训练到loss下降缓慢就可以停止了。
另外,为了进一步加快微调,还可以开启flashattn2, 但它要求GPU架构在sm80以上。
五. 测试结果

符合训练集。
六. 对比LoRA和QLoRA
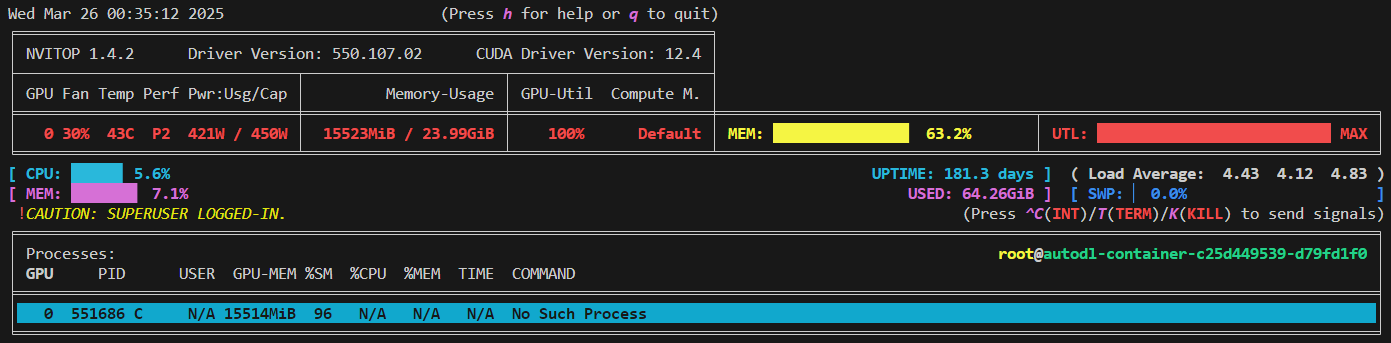
6.1 使用LoRA微调
6.2 使用QLoRA微调
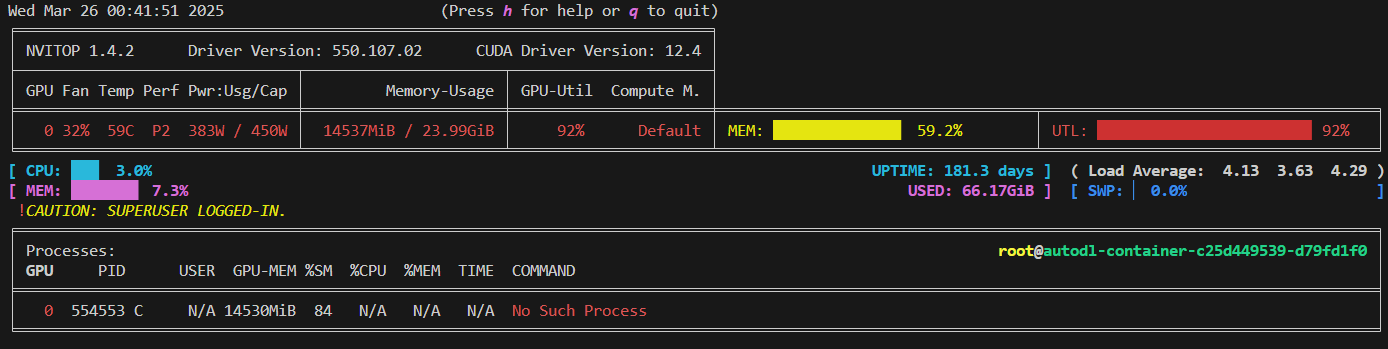
对比LoRA和QLoRA可以看出,QLoRA占用的显存更小,但虽然是int8量化,并不是两倍的关系,因为只是模型参数量化了,由于截断长度是512, 数据占了很大显存,模型只有1.5B,比较小,所以显存降低不明想。
6.3 开启flashttn2优化
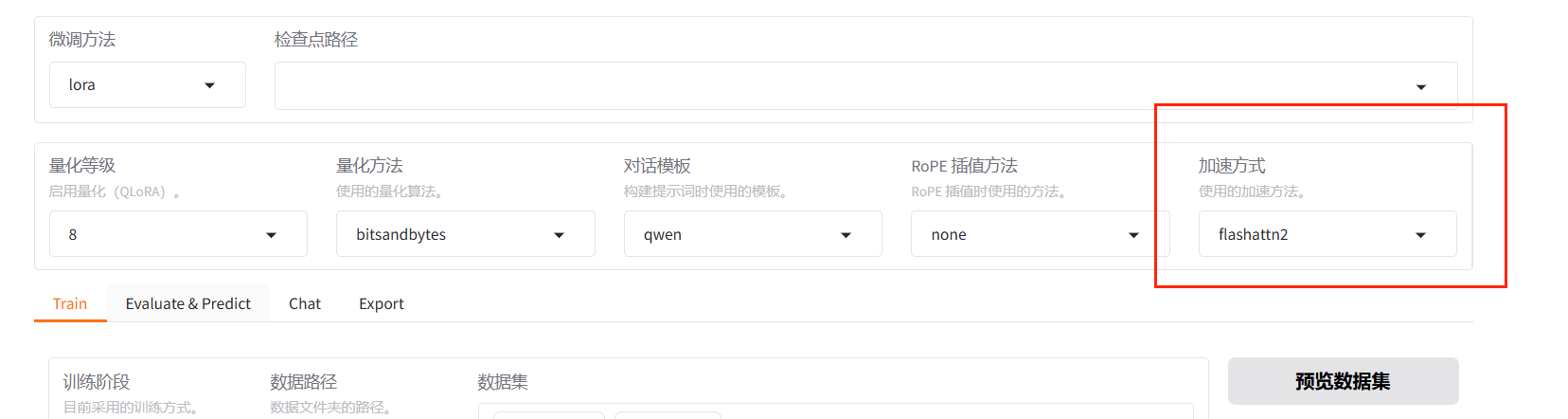
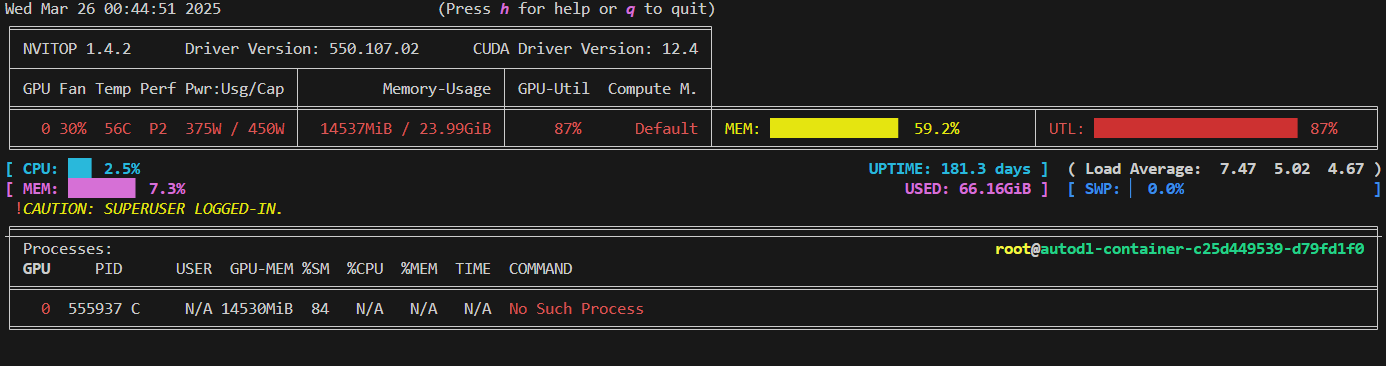
可以看到,开启flashattn2后显存占用变高,但训练速度会更快。
