详细介绍了LLamaFactory和OpenWebui的安装和使用, 以及如何在LLamaFactory上进行推理,微调。以及如何通过脚本对模型进行Lora微调。最后解释量化原理。
一. LLama Factory的安装 我的服务器配置为:
RTX 4090, cuda 12.4 python=3.10 pytorch=2.5.1
本文涉及的所有模型,数据集下载方法参考:
Huggingface的安装和使用 | CodeRQ
参考官网资料即可:
LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub
安装命令,首先拉去llamaFactory代码仓,然后进入代码仓目录,即LLamA-Factory, 接着执行安装指令。
1 2 3 git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e . # 官网要装其他包,但建议先装基础就行,其他的运行时缺啥补啥就行。
可能网络问题连不上git,可以在本地拉取后上传到服务器。
官网给出了使用的三种基本操作:LoRA微调,推理,合并
1 2 3 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml llamafactory-cli chat examples/inference/llama3_lora_sft.yaml llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
但建议直接用可视化界面,监控方便一些。启动界面的时候路径一定要在 LLaMA-Factory中
但是这个界面是在服务器上启动的,本地理论上是访问不到的,如果用vscode,它自带端口转发,会将服务器上的端口转发到本地,可以直接访问。
启动后界面如下:
二. 使用LLamaFacory进行LoRA微调
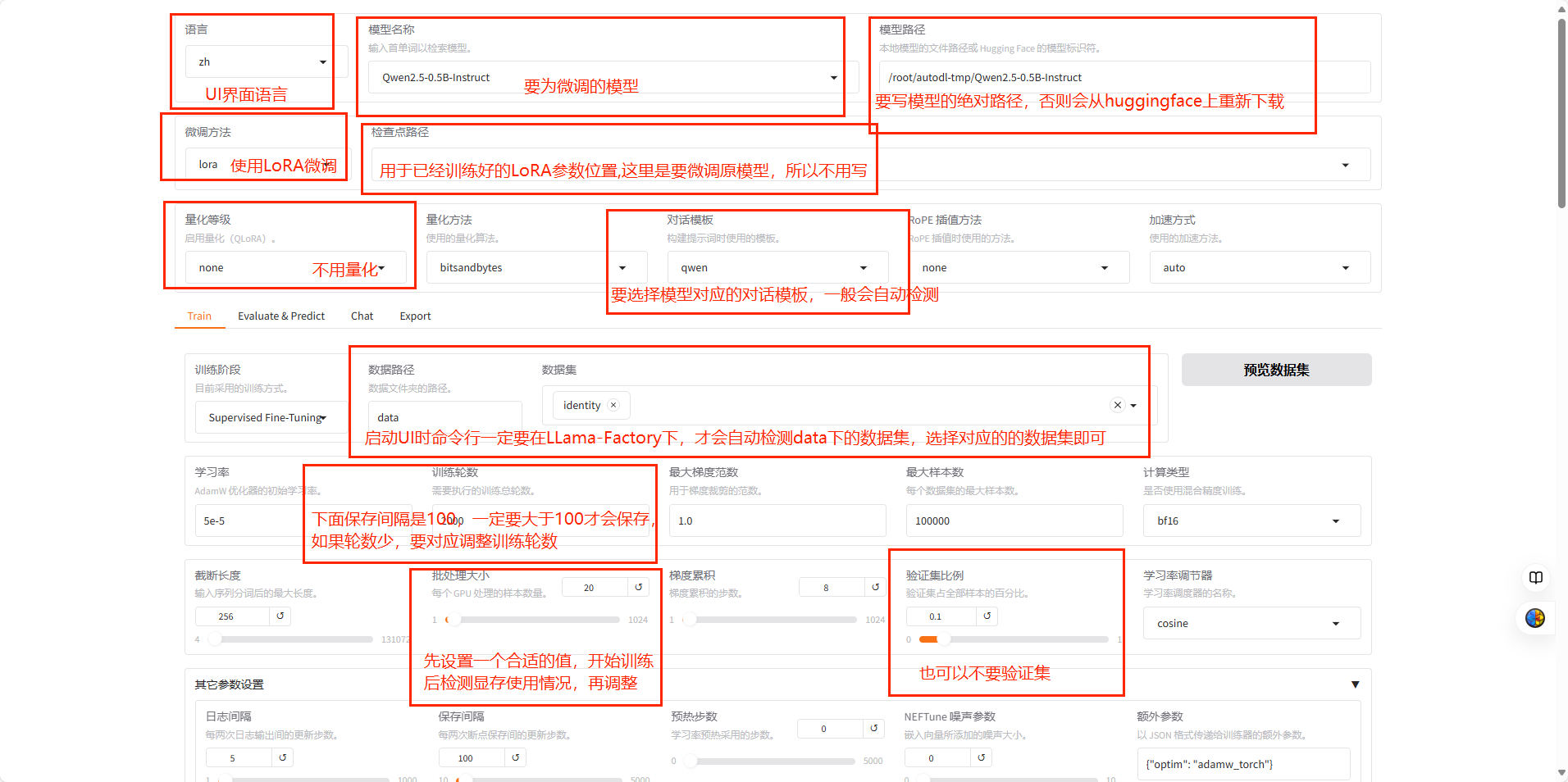
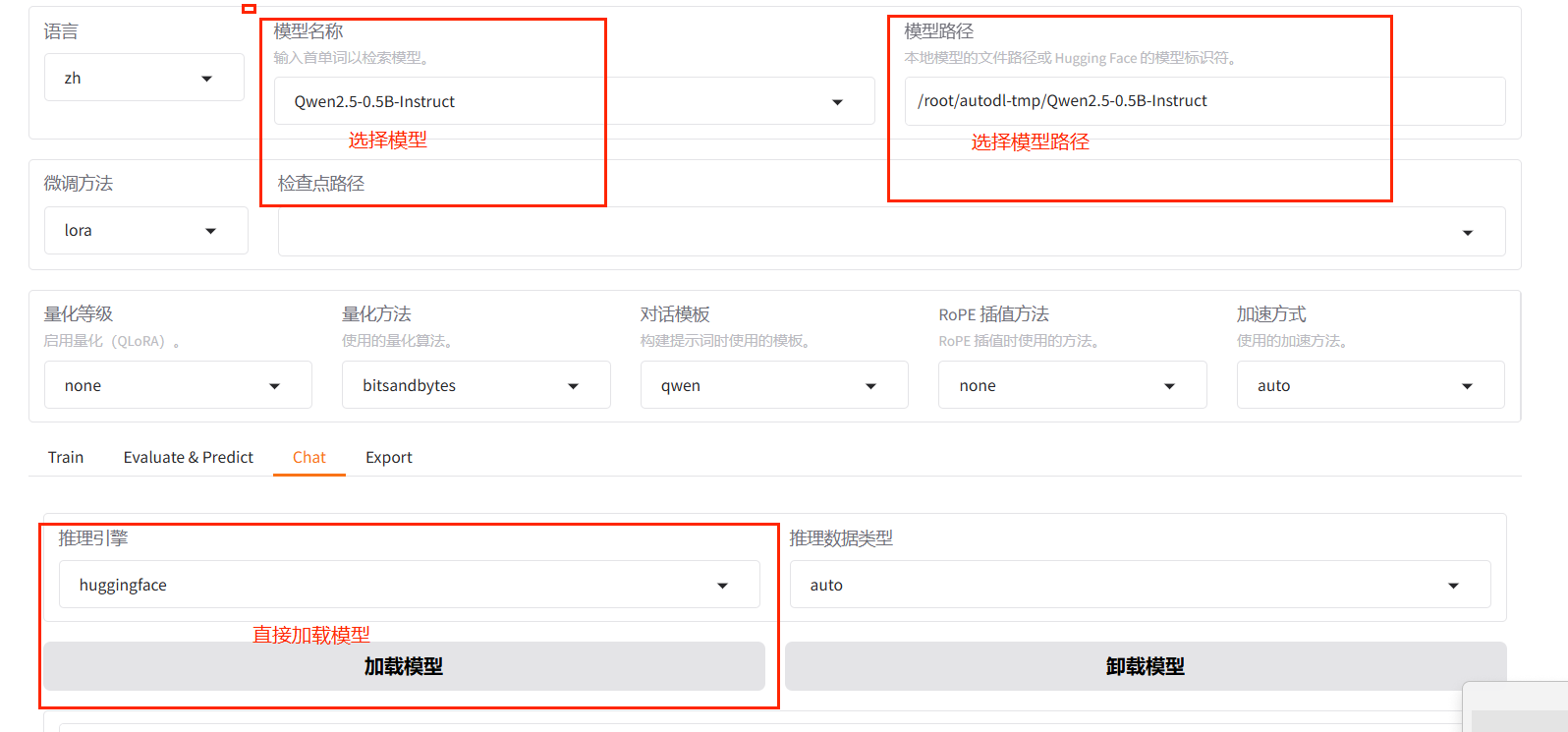
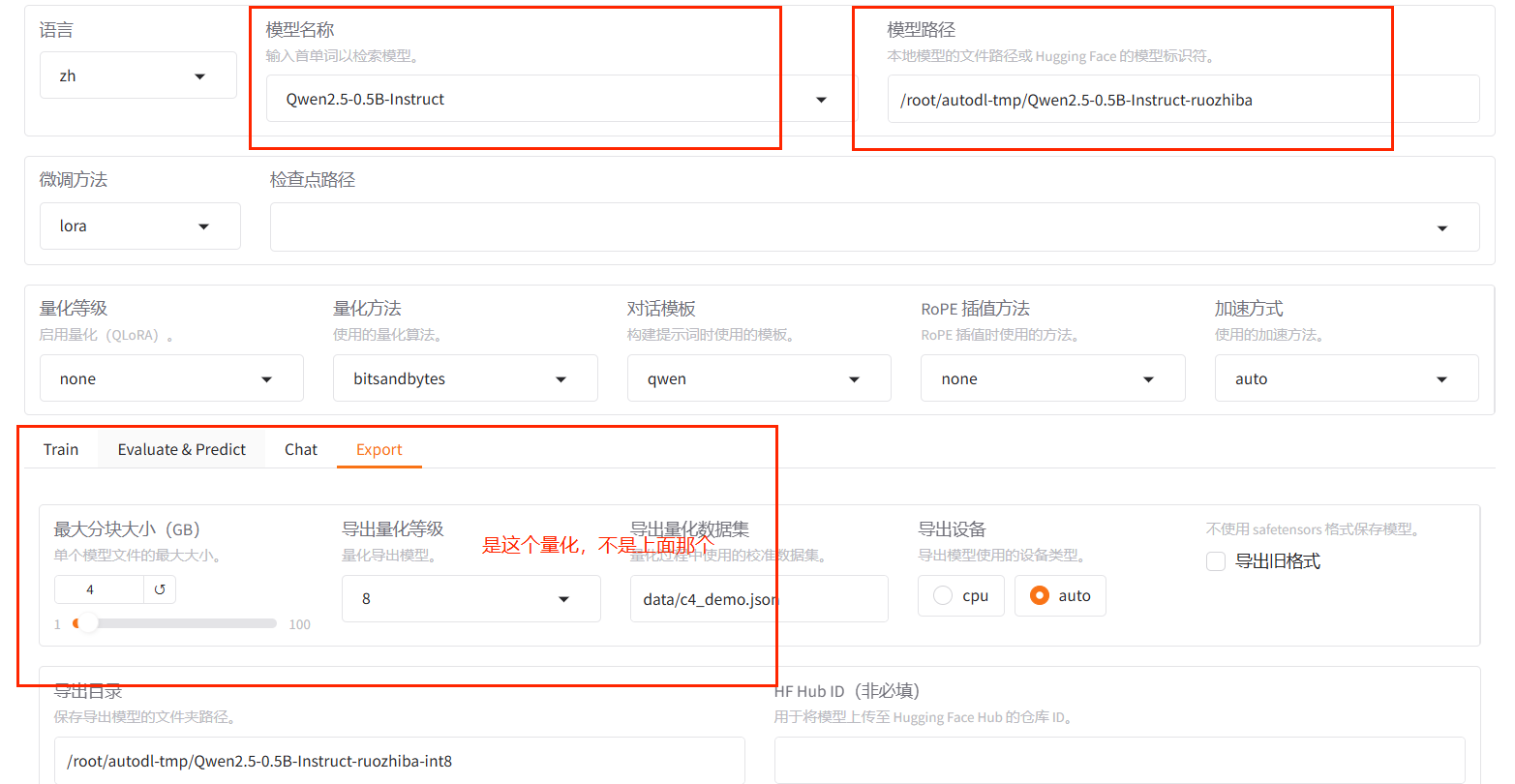
模型
数据集
Qwen2.5-0.5B-Instruct
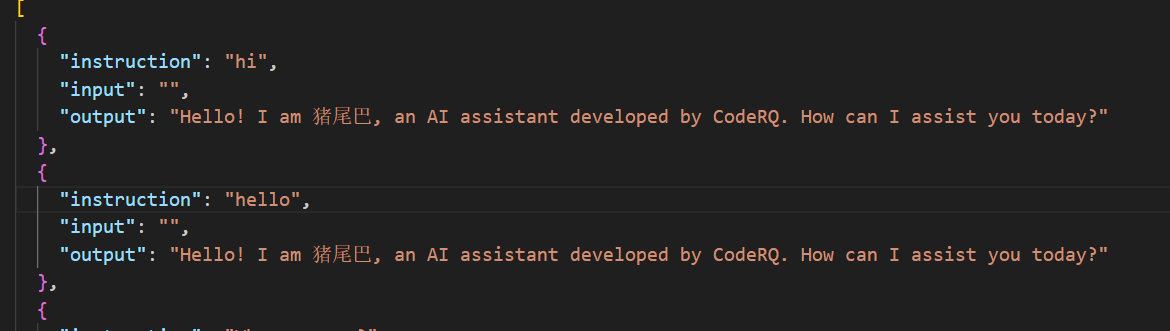
LLamaFactory自带数据集identity.json
2.1 准备数据集 LLamaFactory在文件夹./LLamA-Factory/data/下给出了一些实例数据集,选择其中的identity.json作为微调示例。示例数据如下,将其中的{{name}},{{author}}替换成对应的数据即可。
我修改为如下内容:
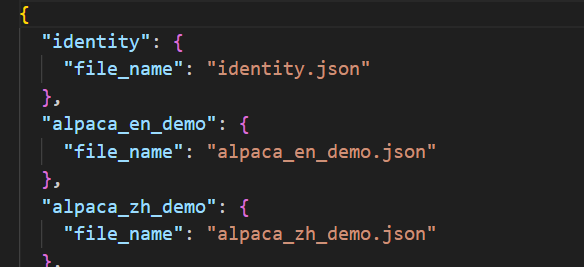
如果是自己准备的数据集,也要放大data目录下,同时在其中的dataset_info.json文件中配置自己数据集的信息,这里使用的是示例数据集,因此已经配置好,配置完在UI界面才可以找到该数据集。
2.2 准备模型 从huggingface上下载qwen2.5-0.5B-Instruct,具体方法见前文。
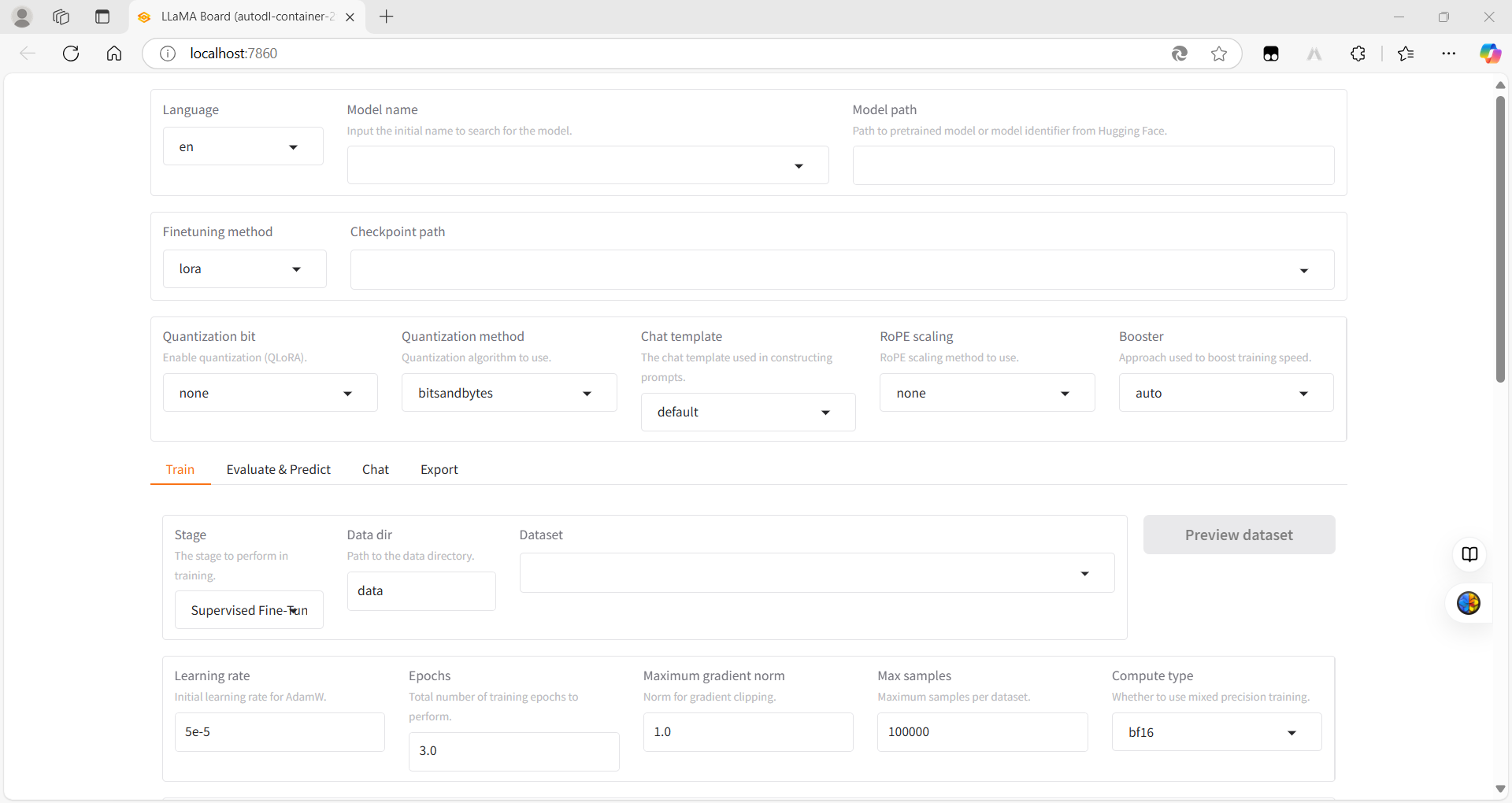
2.3 在UI界面上配置模型和数据,开始LoRA微调 配置如下:
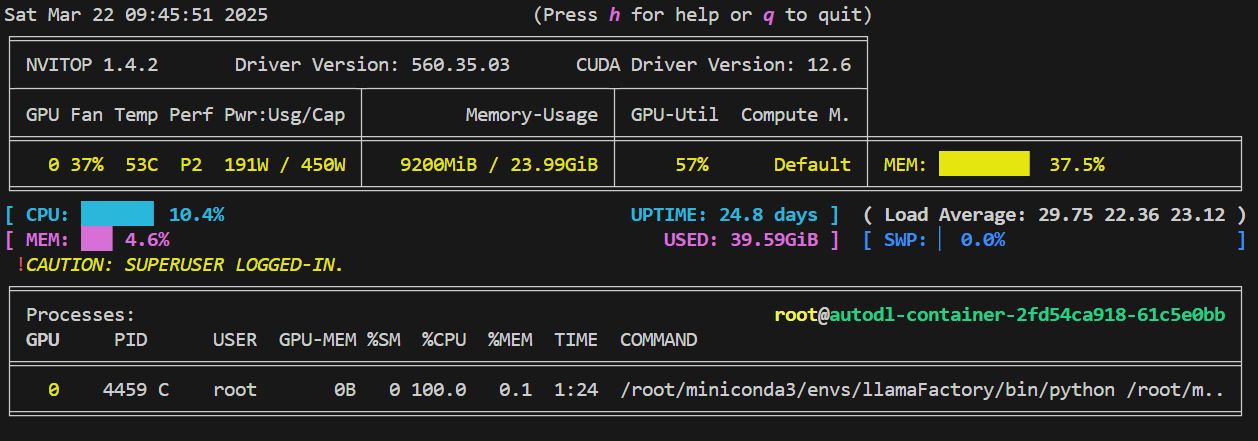
点击开始按钮,开始训练,同时开启新的终端监测GPU使用情况,检测方法前文说过,
这里显存利用率较低,可以增加batch-size,一般怎加到利用率为90%为最佳,我改为50.
如果点击中断后重新开始,会报错(报错要看后台):
这是因为训练结果的保存目录已经创建,它默认不会覆盖,这个目录在LLamaFactory下的saves文件加中,将它里面的东西删除即可。(删到只剩saves)也可以改一下输出目录的名称:
但是发现个问题,AutoDL上训练如果batch-size开太大有问题,显存在动但训练进度不动。我发现设置为10就可以,但显存也没满。AutoDL的毛病,其他服务器应该就不会。
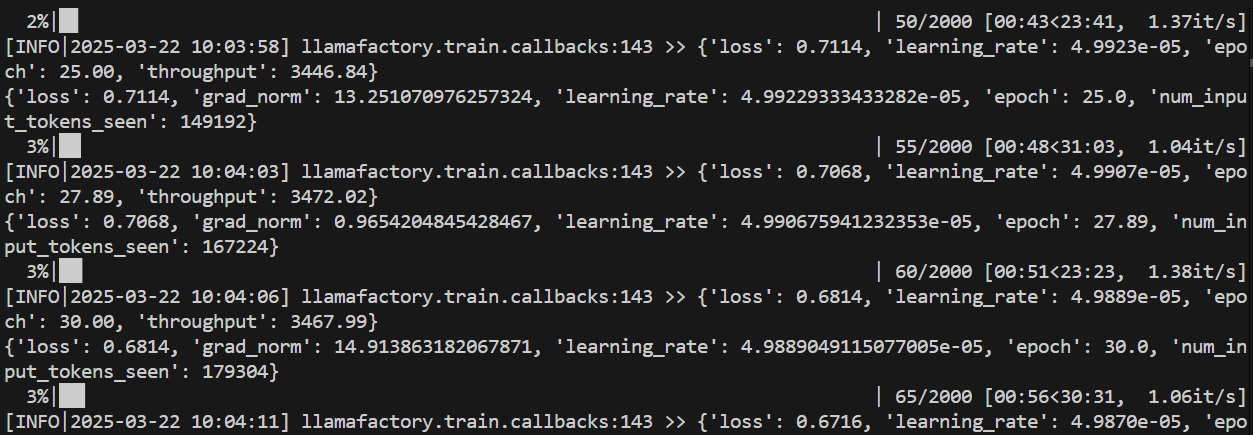
重新点击开始。后台看到训练在进行:
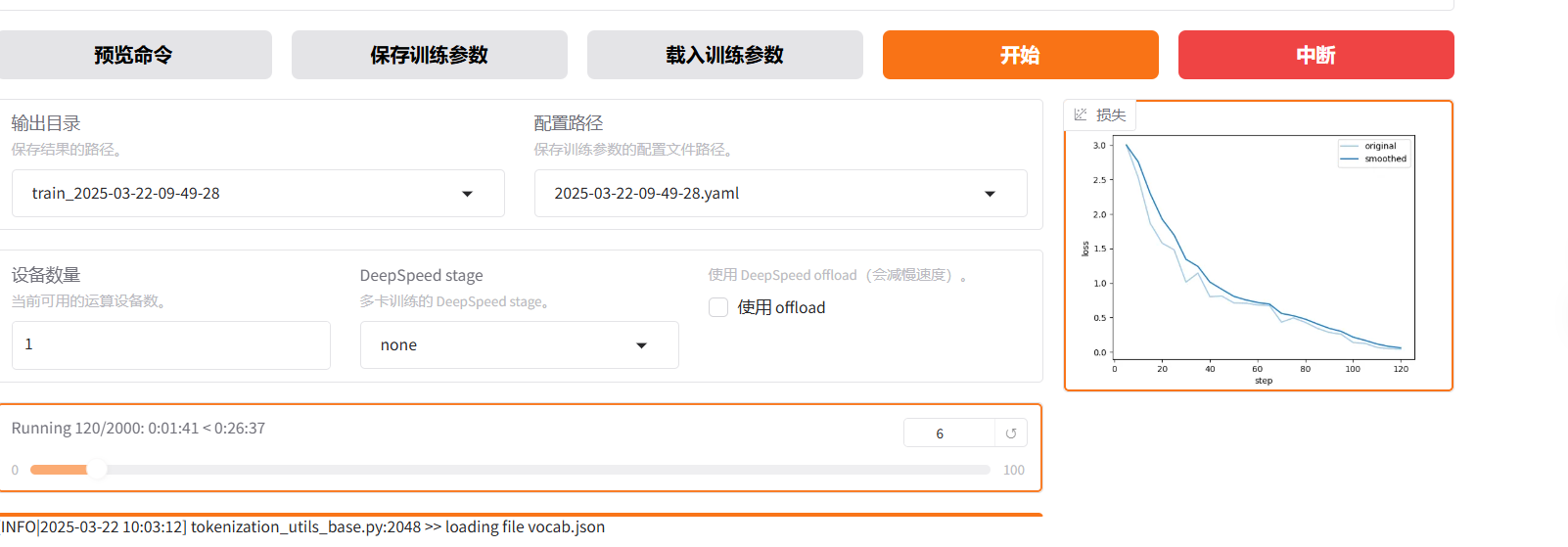
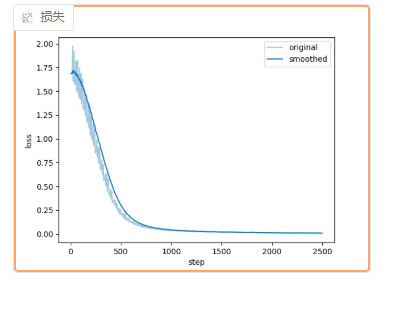
界面中会给出损失曲线:
浅蓝色的是实际的loss曲线,深蓝色是loss曲线平滑后的结果,便于观察趋势,当loss曲线趋于平滑,即变化不大,就可以终止训练了。
训练的权重会保存在saves文件夹下,默认每100个epoch保存一次。
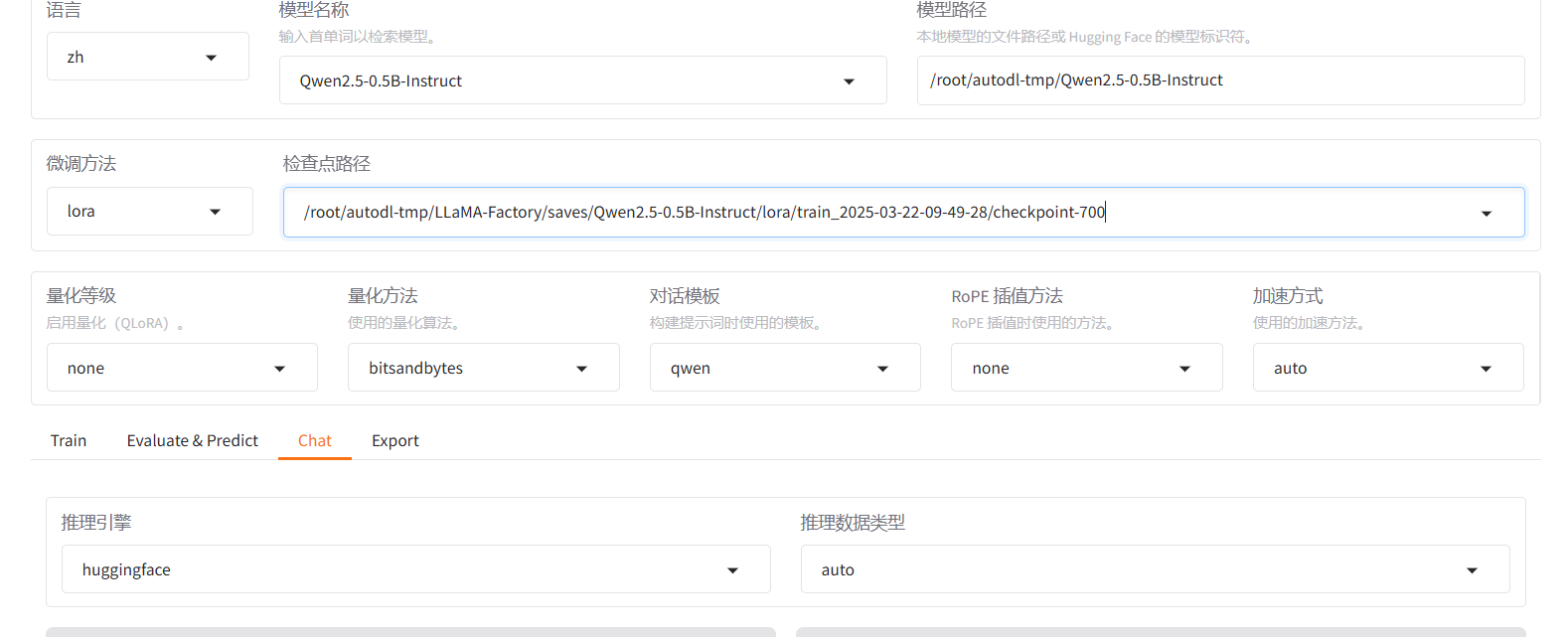
如果中断后想从上次训练的checkpoints继续训练,则加载模型时加载对应的LoRA参数,同时修改输出目录,点击开始即可。
可以看到,一开始loss就很小,说明是从上次的检查点开始的
三. 测试训练效果 使用LLamaFactory的chat功能
3.1首先加载原模型:
可以直接在下面对话款对话,结果如下:
3.2 加载训练后的模型 先卸载刚才的模型,
在检查点路径中选择对应的检查点,绝对路径
点击加载模型
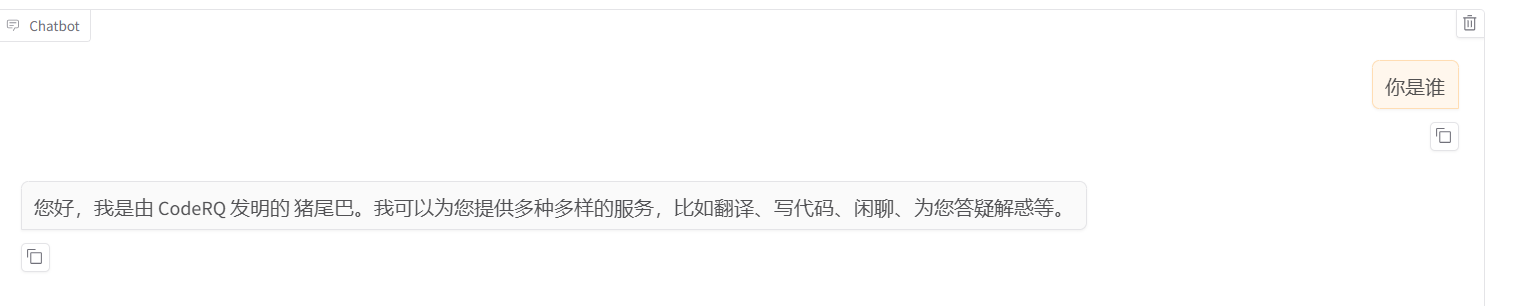
结果如下:
输出和训练数据风格一致,说明训练起效果了。
四. 在自己创建的数据集上微调 4.1 制作训练集 首先从官网上观察数据集格式,数据集是json文件, 其中数据是json object 列表,分为单轮对话和多轮对话。
单轮对话格式如下: 其中instruction才是输入,input 是对instruction的补充,可以为空。
1 2 3 4 5 6 7 8 9 10 11 12 [ { "instruction" : "识别并解释给定列表中的两个科学理论:细胞理论和日心说。" , "input" : "" , "output" : "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元——细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。" } , { "instruction" : "输入三支篮球队的名称并生成一个适当的口号。" , "input" : "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。" , "output" : "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\"" } ]
多轮对话格式如下: 注意,instruction 是本轮对话,即第三轮,并且多轮之间要有逻辑关系,不然微调出来的模型是混乱的。
1 2 3 4 5 6 7 8 9 10 11 12 [ { "instruction" : "人类指令(必填)" , "input" : "人类输入(选填)" , "output" : "模型回答(必填)" , "system" : "系统提示词(选填)" , "history" : [ [ "第一轮指令(选填)" , "第一轮回答(选填)" ] , [ "第二轮指令(选填)" , "第二轮回答(选填)" ] ] } ]
我选择弱智吧的问答作为训练集,可以从HF-mirror下载(下载方法见前文(插入链接 )LooksJuicy/ruozhiba 内容如下:
1 2 3 4 5 6 7 8 9 10 [ { "instruction" : "只剩一个心脏了还能活吗?" , "output" : "能,人本来就只有一个心脏。" } , { "instruction" : "爸爸再婚,我是不是就有了个新娘?" , "output" : "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。" } , ]
要把它转为LLamaFactory可以识别的格式,转化脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 import jsonwith open ('./data/ruozhiba/ruozhiba_qa.json' , 'r' , encoding='utf-8' ) as file: data_list = json.load(file) result_list = [] for each in data_list: result_list.append({"instruction" :each['instruction' ], "input" : "" , "output" : each['output' ]}) print (len (result_list))with open ("./data/ruozhiba/duozhiba_qa_llamaFactory.json" , 'w' , encoding='utf-8' ) as file: json.dump(result_list, file, ensure_ascii=False , indent=4 )
修改后格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 [ { "instruction" : "只剩一个心脏了还能活吗?" , "input" : "" , "output" : "能,人本来就只有一个心脏。" } , { "instruction" : "爸爸再婚,我是不是就有了个新娘?" , "input" : "" , "output" : "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。" } ]
4.2 模型微调 注意配置数据集时先将处理好的数据集放到data目录下,然后在dataset_info.json 中配置文件信息。插入:
1 2 3 "duozhiba_qa_llamaFactory" : { "file_name" : "duozhiba_qa_llamaFactory.json" } ,
参考3.3的配置方法,微调Qwen2.5-0.5B-Instruct, 另外,可以选择多个数据集,会混合起来训练。
训练到损失趋于平缓即可停止。
五. 测试训练效果 LLama-Factory给出了三种微调后的处理方式:Evaluation&Predict(测试), Chat(对话),Export(模型合并,量化)
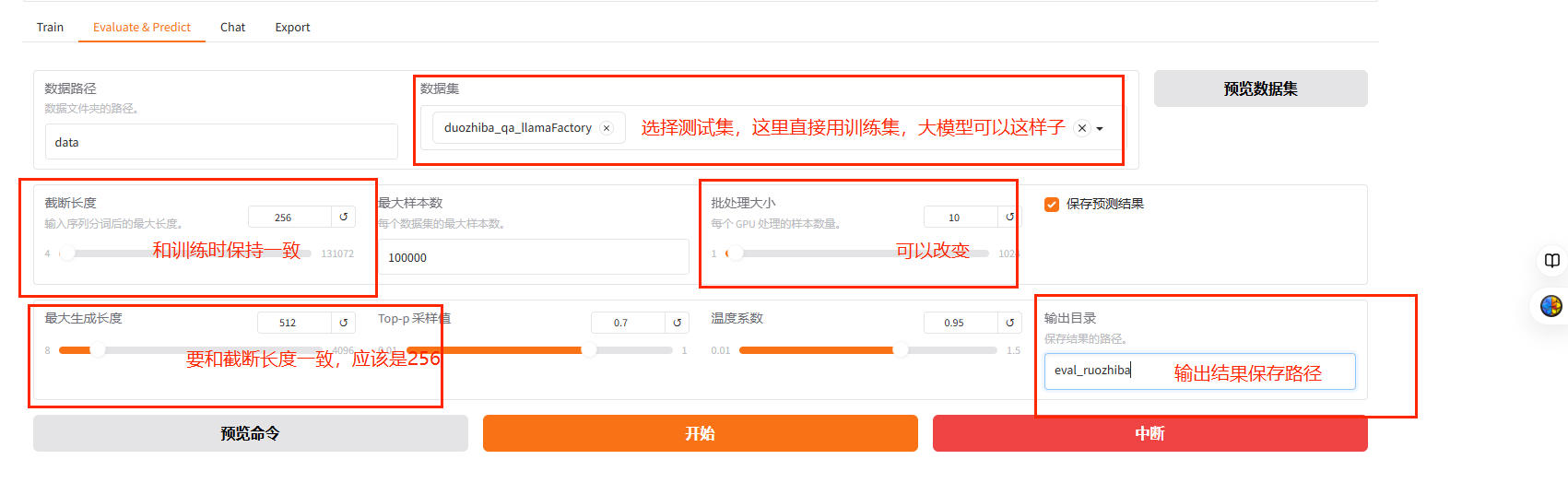
5.1 Evaluation & Predict 选择模型,最后保存的checkpoint,测试集(如果没有特别划分,可以直接用训练集,这里直接用训练集),截断长度和训练时一致,batch_size可以改变,具体配置如下:
点击开始,后台会报错,因为一些依赖没有安装,缺啥补啥就行。
只会进行一个epoch。测试结果如下:
1 2 3 4 5 6 7 8 9 10 { "predict_bleu-4": 88.64074418449198, "predict_model_preparation_time": 0.0065, "predict_rouge-1": 92.81370474598931, "predict_rouge-2": 90.33300949197861, "predict_rouge-l": 91.9221340909091, "predict_runtime": 329.3329, "predict_samples_per_second": 4.543, "predict_steps_per_second": 0.455 }
各个指标的含义在8.1中解释。
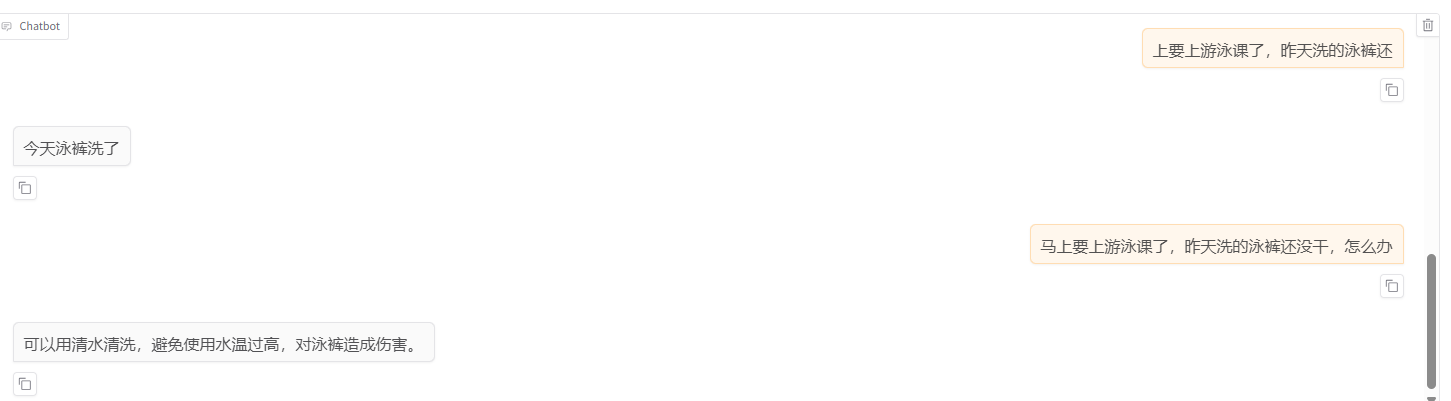
5.2 chat 同 四,加载基座模型,设置LoRA配置即可。
效果如下:
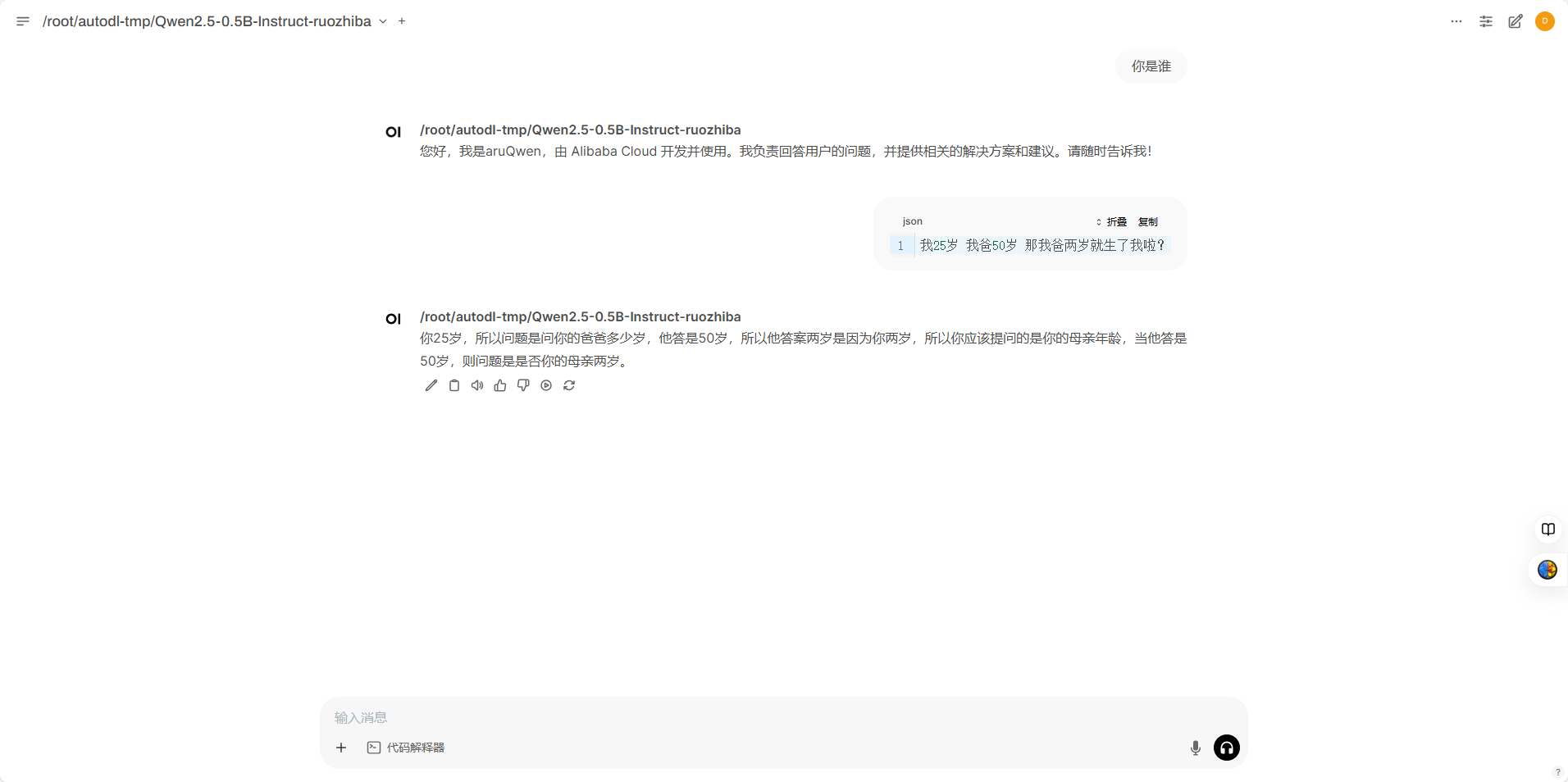
和训练数据类似,说明微调起效果了。
注意: 每次输入一次对话产生输出后,要清空历史,chat对话框默认是上下文对话,如果不清空历史,上文会影响本轮输出,结果会出错。比如
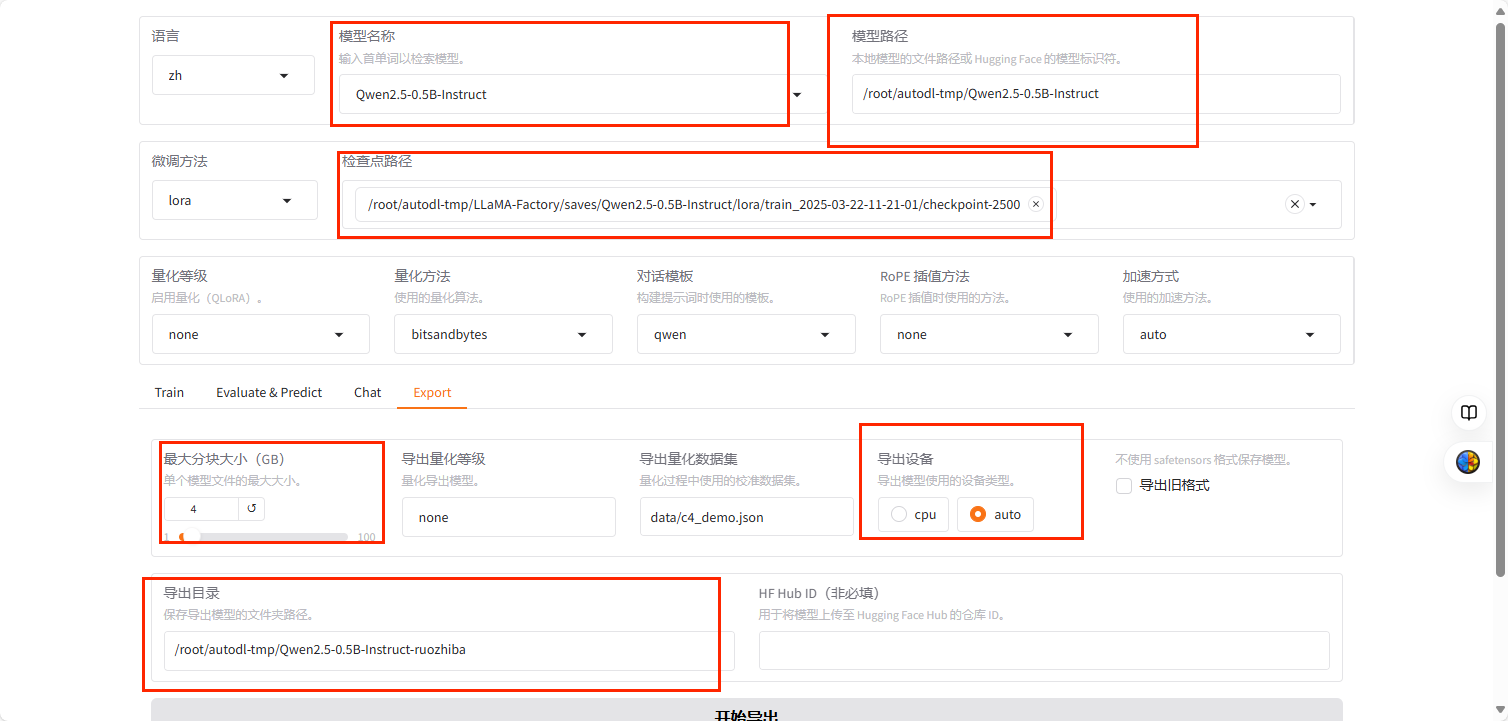
5.3 合并模型Export 设置好基座模型,LoRA路径,导出目录即可。
其中最大分块大小一般选4G,因为一些机器超过4会有问题。
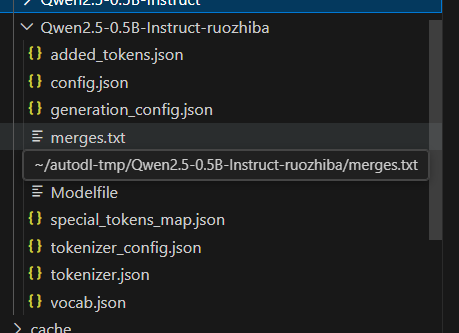
点击开始。导出后会在目标路径生成一个和base模型格式一样的文件
直接运行该模型就能得到微调后的效果。
5.4 量化 量化主要时用int8甚至更少的比特数表示参数,是为了降低对硬件的依赖,但同样的会造成模型效果的变差,这里量化微调后的模型,LLama-Factory只支持量化合并后的模型,所以只能合并后再量化.
这里量化到int8,量化过程中需要校准,校准数据集都可以,具体校准方法在补充中说明。
需要安装一些包,缺啥补啥就行
注意:auto-gptq包和pytorch版本,cuda版本,python版本有关,我的版本可以直接安装,有时不可以,就先创建一个新的虚拟环境(按照我的配置,特别是python,cuda,pytorch) 然后先安装auto-gtpq,再安装llamafactory,就不容易出错。
另外,量化过程需要从huggingface上下载文件,如果服务器没有梯子,可以配置huggingface国内源,方法之前的文章有写,直接用命令
1 export HF_ENDPOINT=https://hf-mirror.com
量化完成后出现量化后的模型:
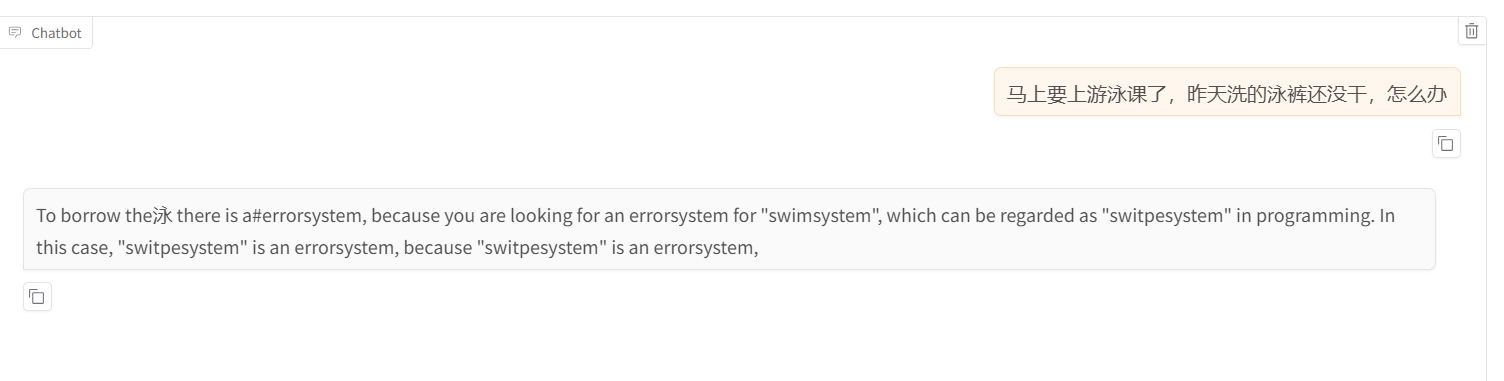
测试该模型效果:
结果混乱了,并不是量化过程出错。但说明这次量化失败了,主要这个模型本来就很小,量化后精度损失太大了,按理来说,模型越大,量化后精度损失越小。
六. 使用OpenWebui 6.1 open webui 下载 注意:openwebui要在python=3.11下安装,所以要新开一个虚拟环境,新开后直接安装就行
1 2 3 conda create -n openwebui python==3.11 -y conda activate openwebui pip install open-webui
6.2 启动 首先启动vllm,启动教程前面文章讲过了: ollama,vllm,LMDeploy 部署大模型 | CodeRQ
也可以用其他工具部署,只要记住接口就行了。
接着启动open-webui
启动前要配置几个东西:
1 2 3 export HF_ENDPOINT=https://hf-mirror.com # 要从huggingface下载东西,配置国内huggingface镜像源 export ENABLE_OLLAMA_API=False # open-webui默认用ollama部署,如果用的vllm或者其他,则关闭,如果用ollama就不用 export OPENAI_API_BASE_URL=http://127.0.0.1:8000/v1 # 服务对应的端口,vllm端口在8000
配置完了直接启动
就会启动了,但第一次启动会比较慢,要安装东西,要等一等。
我这里服务器卡住了,按理到这里就是成功了,会弹窗出来。
6.3 解决弹不出窗口的问题 一开始我以为是服务器问题,没有深究,后来通过查阅资料,发现是新版Ollama的问题,我们之前启动LLama-Factory的时候其实服务是启动在服务器上的,之所以我们本地能通过浏览器访问,是因为vscode帮我们做了端口转发,而open-webui启动的时候不会自动做端口转发,所以我们需要自己做端口转发。
在vscode中配置端口转发,把服务器的8080端口转发到本地,即可在本地打开
首次登录需要设置邮箱密码。
设置完密码还需要等很久,之后会出现对话界面
七. 通过脚本直接Lora微调Qwen 参考连接 self-llm/examples/Chat-嬛嬛/readme.md at master · datawhalechina/self-llm
主要LoRA微调 Qwen2.5-0.5B-Instruct,使其输出分格类似甄嬛。直接通过脚本微调。
7.1 获取数据集 通过以下链接获取,然后上传到服务器。 self-llm/dataset/huanhuan.json at master · datawhalechina/self-llm
7.2 配置环境 我的配置为: PyTorch 2.5.1; Python 3.12(ubuntu22.04); CUDA 12.4
1 2 3 conda create -n myenv python==3.12 -y conda activate myenv pip install transformers accelerate peft datasets
7.3 模型微调 可以参考 3.3和5.2 的方法使用LLama-Factory进行微调,这里展示直接通过脚本微调的方式。训练代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from datasets import Datasetimport pandas as pdimport torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer, GenerationConfigfrom peft import LoraConfig, TaskType, get_peft_modelmodel_path = "" train_path = "" output_path = "" def process_func (example ): MAX_LENGTH = 384 input_ids, attention_mask, labels = [], [], [] instruction = tokenizer(f"<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\n现在你要扮演皇帝身边的女人--甄嬛<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n{example['instruction' ] + example['input' ]} <|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" , add_special_tokens=False ) response = tokenizer(f"{example['output' ]} <|eot_id|>" , add_special_tokens=False ) input_ids = instruction["input_ids" ] + response["input_ids" ] + [tokenizer.pad_token_id] attention_mask = instruction["attention_mask" ] + response["attention_mask" ] + [1 ] labels = [-100 ] * len (instruction["input_ids" ]) + response["input_ids" ] + [tokenizer.pad_token_id] return { "input_ids" : input_ids, "attention_mask" : attention_mask, "labels" : labels } if __name__ == "__main__" : model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto" ,torch_dtype=torch.bfloat16) model.enable_input_require_grads() tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False , trust_remote_code=True ) tokenizer.pad_token = tokenizer.eos_token df = pd.read_json(train_path) ds = Dataset.from_pandas(df) tokenized_id = ds.map (process_func, remove_columns=ds.column_names) config = LoraConfig( task_type=TaskType.CAUSAL_LM, target_modules=["q_proj" , "k_proj" , "v_proj" , "o_proj" , "gate_proj" , "up_proj" , "down_proj" ], inference_mode=False , r=8 , lora_alpha=32 , lora_dropout=0.1 ) model = get_peft_model(model, config) model.print_trainable_parameters() args = TrainingArguments( output_dir=output_path, per_device_train_batch_size=4 , gradient_accumulation_steps=4 , logging_steps=10 , num_train_epochs=3 , save_steps=100 , learning_rate=1e-4 , save_on_each_node=True , gradient_checkpointing=True ) trainer = Trainer( model=model, args=args, train_dataset=tokenized_id, data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True ), ) trainer.train()
运行train.py ,开始训练:
8.4 模型合并 训练是输出是lora参数,并不是整个模型,如果想用vllm或者其他工具部署,可以将lora参数合并到基座模型,导出微调后的整个模型。合并和导出代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import torchfrom peft import PeftModelfrom transformers import AutoTokenizer, AutoModelForCausalLM, LlamaTokenizerfrom transformers.generation.utils import GenerationConfig def apply_lora (model_name_or_path, output_path, lora_path ): print (f"Loading the base model from {model_name_or_path} " ) base_tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False , trust_remote_code=True ) base = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="cuda:0" , torch_dtype=torch.bfloat16, trust_remote_code=True ) print (f"Loading the LoRA adapter from {lora_path} " ) lora_model = PeftModel.from_pretrained( base, lora_path, torch_dtype=torch.float16, ) print ("Applying the LoRA" ) model = lora_model.merge_and_unload() print (f"Saving the target model to {output_path} " ) model.save_pretrained(output_path) base_tokenizer.save_pretrained(output_path) if __name__ == "__main__" : lora_path = "/root/autodl-tmp/output/huanhuan-lora/checkpoint-699" model_path = "/root/autodl-tmp/Qwen2.5-0.5B-Instruct" output = "/root/autodl-tmp/Qwen2.5-0.5B-Instruct-huanhuan" apply_lora(model_path,output,lora_path)
8.5 测试模型 合并后的模型和基座模型结构一样,可以用上面的工具部署,这里仅为了测试效果,所以直接通过脚本测试。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "/root/autodl-tmp/Qwen2.5-0.5B-Instruct-huanhuan" model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto" , device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name) prompt = "你是谁?" messages = [ {"role" : "system" , "content" : "现在你要扮演皇帝身边的女人--甄嬛" }, {"role" : "user" , "content" : prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False , add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt" ).to(model.device) generated_ids = model.generate( **model_inputs, max_new_tokens=512 ) generated_ids = [ output_ids[len (input_ids):] for input_ids, output_ids in zip (model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True )[0 ] print (response)
运行后输出如下:
符合预期效果,说明微调起效。
八. 补充 8.1 LLamaFactory evaluation中各个指标的含义 在 5.1 中通过LLama-Factory进行测试,结果如下:
1 2 3 4 5 6 7 8 9 10 { "predict_bleu-4": 88.64074418449198, "predict_model_preparation_time": 0.0065, "predict_rouge-1": 92.81370474598931, "predict_rouge-2": 90.33300949197861, "predict_rouge-l": 91.9221340909091, "predict_runtime": 329.3329, "predict_samples_per_second": 4.543, "predict_steps_per_second": 0.455 }
这几个结果的含义如下:
predict_bleu-4
8.2 量化校准的原理 8.2.1 为什么需要量化 量化的主要目的是节约显存,提升计算效率以及加快通信。如下表,deepseek-r1-7b模型以不同类ing加载和随不同数据类型所占用的显存也不一样
FP32
FP16
Int8
Int3
显存占用
28G
14G
7G
3.5G
总的来说,量化就是把Float类型(FP32,FP16)的模型参数和激活值,用整数(Int8. Int4)来代替,同时尽可能减少量化后模型推理的误差。
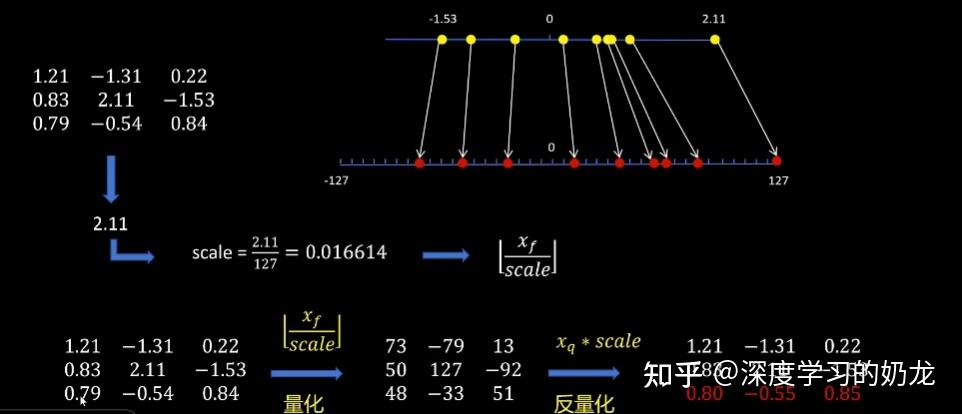
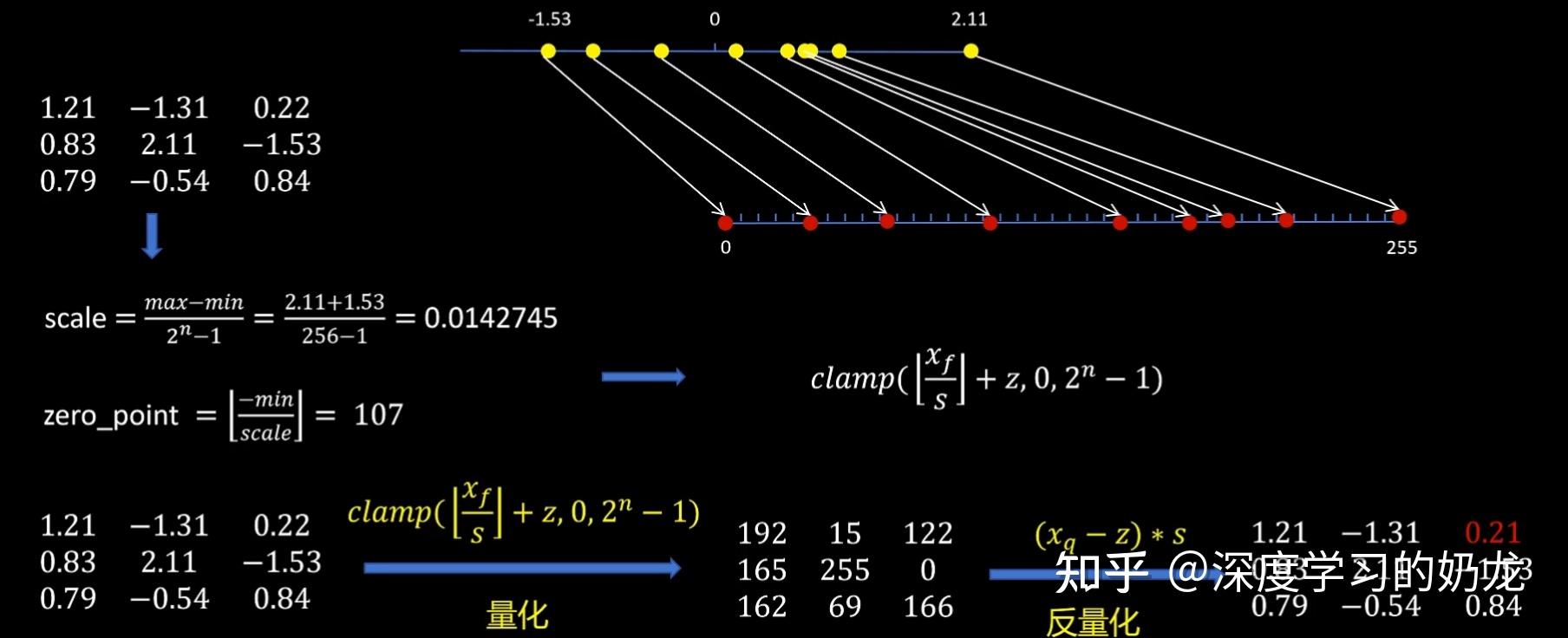
8.2.2 对称量化vs非对称量化 (1)对称量化: 如下图,对称量化的原理就是找到, xf 中绝对值的最大值,然后对其进行缩放得到量化后的值,然后进行反量化得到原来的值,可以看出量化是存在一定误差的,具体原理如下图:
这样量化的缺点就是,坐标轴上有一段数值空间被浪费了,对应图中-127那一部分。基于这个缺点,为了让量化后的坐标轴上的数值被充分利用,引入非对称量化。
(2)非对称量化: 非对称量化有一个额外的参数Z调整零点的映射,这个参数通常称为零点。非对称量化表示的范围没有严格的限制,可以根据浮点值的范围,选取任意的想要表示的范围。因此非对称量化的效果通常比对称量化好,但是需要额外存储以及推理时计算零点相关的内容。
因此,对称量化具有计算简单,精度低等特点,非对称量化的计算有一个额外的参数Z调整零点的映射,因此计算复杂,但精度相对较高。
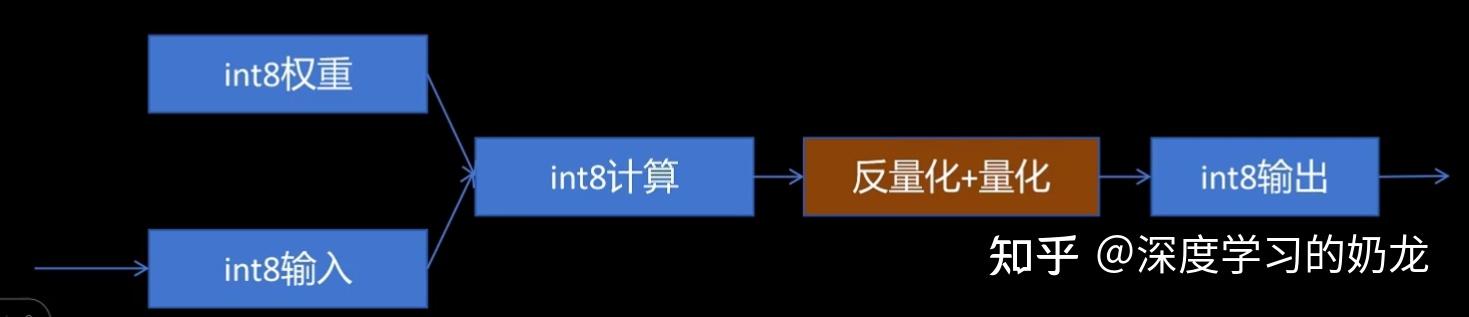
(3)在矩阵乘法中的应用 :下图为对称量化在居中乘法当中的应用示意图(非对称量化也类似),通过量化,可以把浮点矩阵的乘法,转化为整数矩阵的乘法,虽然存在一定误差,但误差不大。在矩阵乘法中采用量化可以降低计算复杂度,提升矩阵乘法效率。
8.2.3 如何对神经网络进行量化 为什么量化对神经网络精度影响不大?
因为一般权重和输入都经过Normalization, 基本数值范围都不大。
因为激活函数,数值影响会被平滑。
绝大部分神经网络都是分类问题,最后都是概率值,只要最后某种类别的概率高于其他类别就可以,不需要绝对数值。
8.2.4 动态量化vs静态量化 量化在神经网络中的是对每一层而言,每一层进行量化计算,每一层输出时进行反量化。具体而言,量化在神经网络当中的应用又可分为动态量化(Post Training Quantization Dynamic, PTQ Dynamic)与静态量化(Post Training Quantization Static), PTQ Static
(1) 动态量化流程
将训练好的模型权重量化为Int8,并保存量化参数。
在模型推理时,对每一层输入的FP32激活值,动态进行量化为Int8。
在每一层对量化后的Int8权重和Int8激活值进行计算。
在每一层输出时将结果反量化为FP32。
将FP32激活值传入到下一层。
可用下图表示:
动态量化存在的问题:
每一次推理每一层都要对输入统计量化参数,耗时。
每一层计算完都转化为FP32,存入显存,占用显存带宽。
(2)静态量化流程
针对动态量化的问题1,通过用有代表性的输入数据跑一遍整个网络,通过统计得到每层大概的量化参数来解决;问题2,这一层的输出是下一层的输入。下一层还是要量化,通过在这一层直接量化好再传给下一层方法来解决。这就是静态量化。
将训练好的模型权重量化为Int8, 并保存量化参数。
校准:利用一些数据进行模型推理,用这些数据在神经网络每一层产生的激活估算除激活值的量化参数。这样就不用推理时每次根据实际激活值计算量化参数。
在每一层对量化后的Int8权重和Int8激活值进行计算。
在每一层输出时将结果反量化为FP32,同时根据校准产生的激活值量化参数,把激活值量化为Int8,把量化参数放入量化后的激活值中。
将Int8的激活值和它的量化参数传入到下一层。
可用下图表示:
8.3 提醒 整个项目东西有点多,有几点容易出错:
时刻注意,你要在虚拟环境中,开启webui的命令行路径在LLama-Factory文件夹中。
有时下载包后仍显示没有该包,要重启终端。
尽量用python3.10,兼容性好一些。
openwebui要用python3.11