介绍如何从modelscope下载模型,以及三种常用的本地模型部署工具 ollama,vllm, LMDeploy 的下载,部署和调用方法。
一. 从modelscope下载模型
modelscope和huggingface类似,但魔塔社区是国内网站,下载比较快,但模型比huggingface少, 平时下载还是推荐从hf-mirror下载。
可以参考 大模型应用系列(二) Huggingface的安装和使用 | 乌漆嘛黑
下载方式和huggingface类似,首先安装modelscope
接着下载模型
1
| modelscope download --model Qwen/QwQ-32B --local_dir ./dir
|
另外,魔塔社区现在提供36小时的云服务器,可以白嫖,选择一个模型,点击下图中的Notebook快速开发
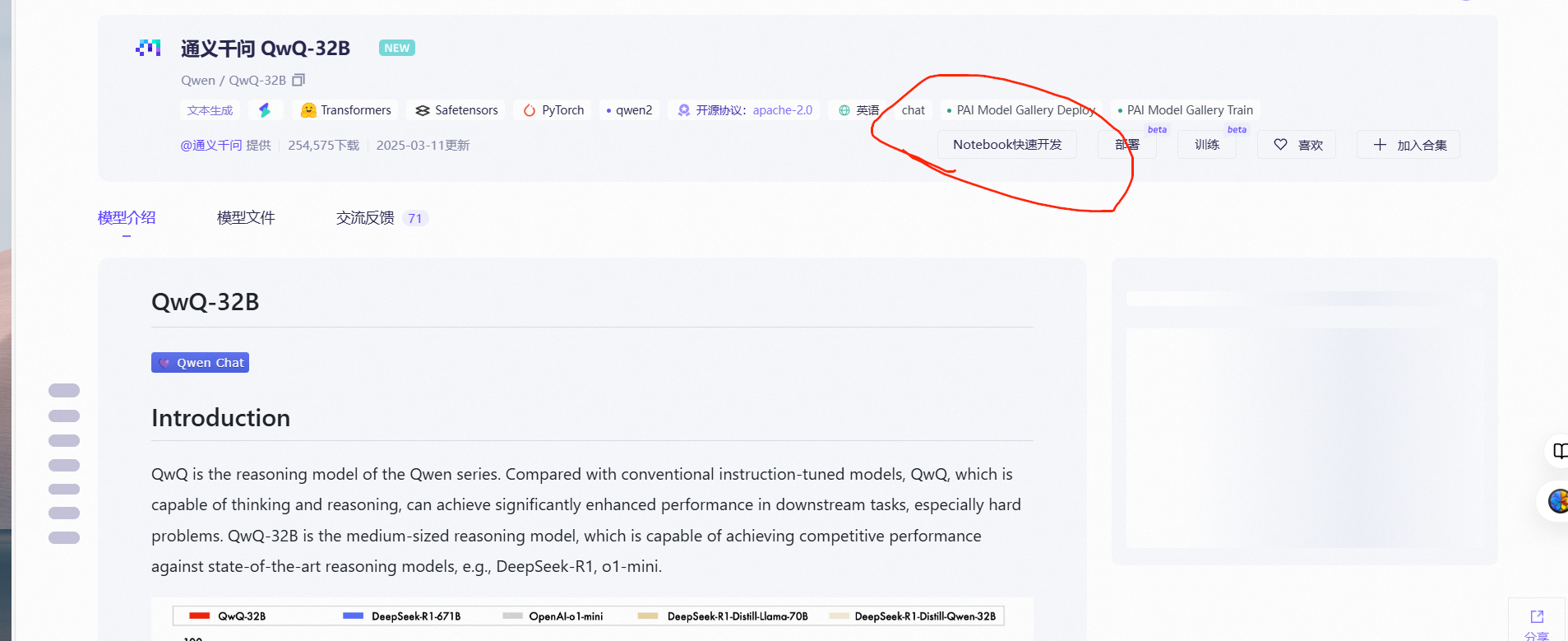
可以选择两种服务器,其中CPU服务器是无限的,新用户GPU服务器有36个小时。
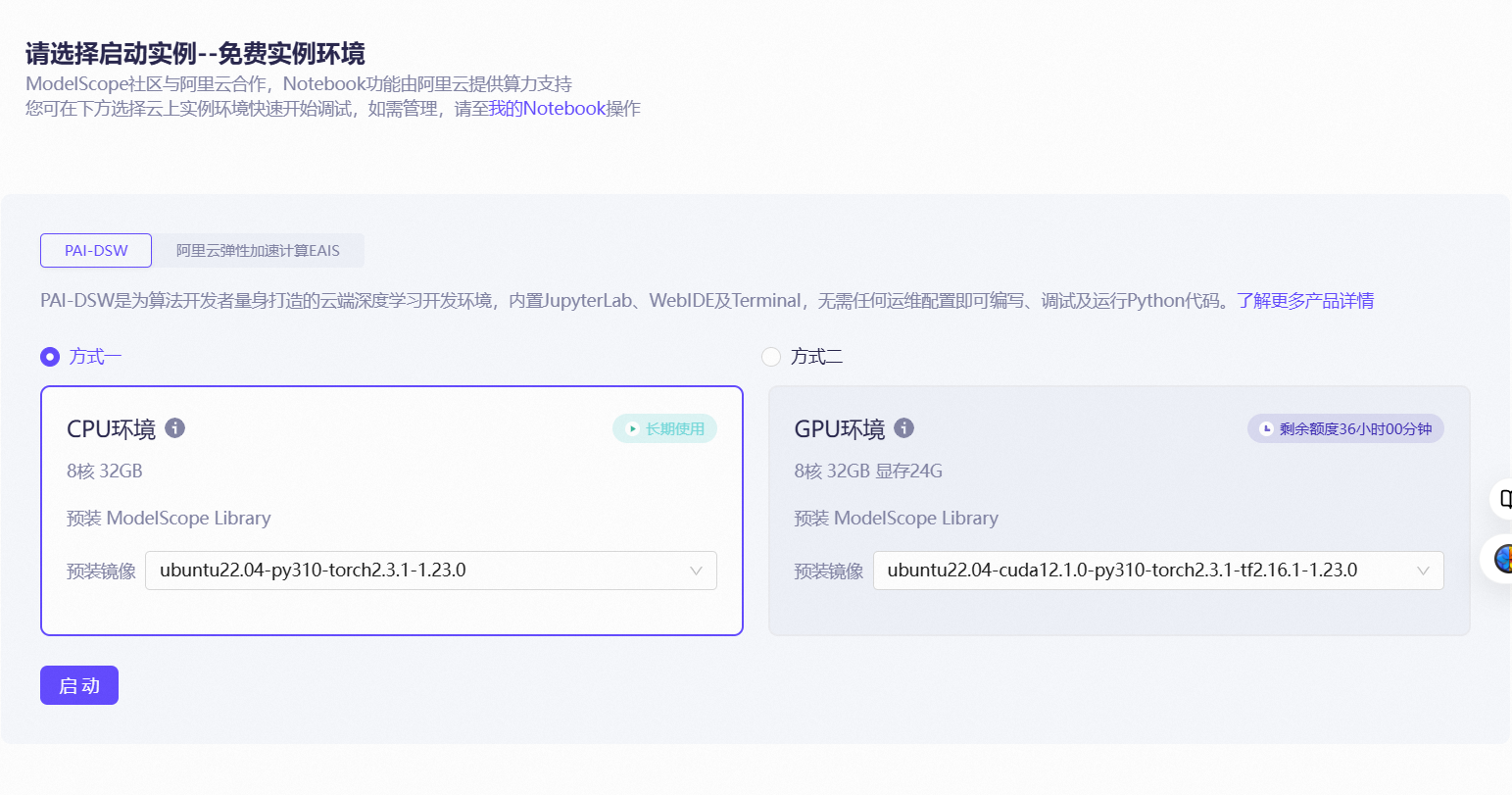
选择合适的基础镜像,即可开机,但不能SSH远程连接。
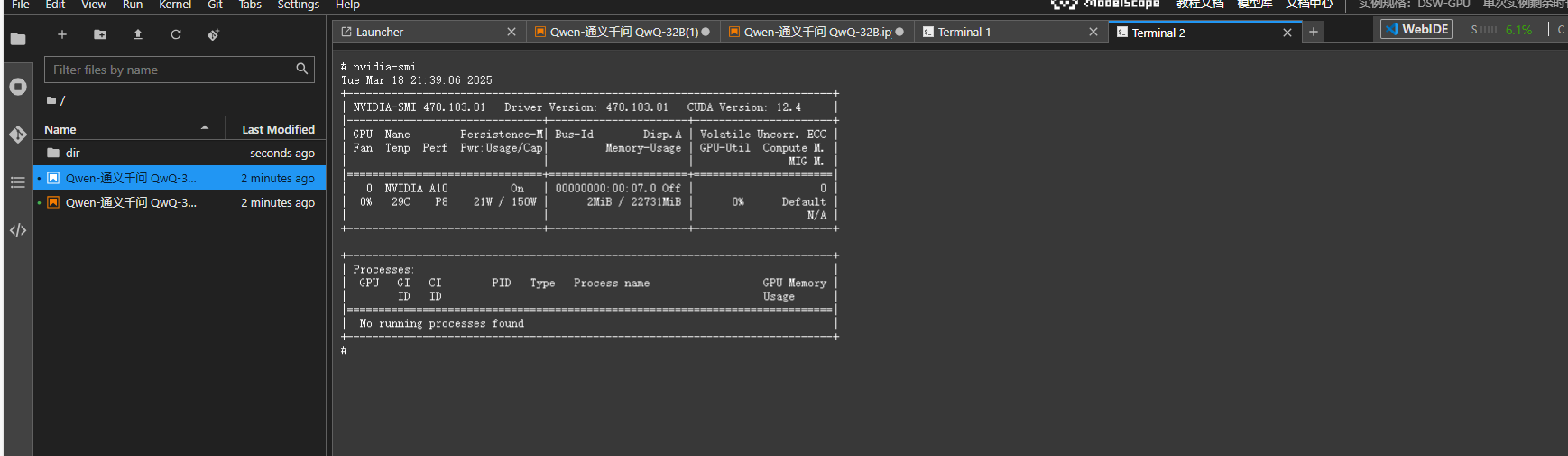
可以看到,提供了一张A10GPU。
二. 本地调用Qwen模型
和之前用GPT2模型类似,首先加载模型和分词器,接着封装信息,输入到模型获取输出。具体模型如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| from modelscope import AutoModelForCausalLM, AutoTokenizer
model_path = "./Qwen2.5-0.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
prompt = "讲一个猫和老鼠的故事"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
|
运行后输出如下:

三. Ollama 部署Qwen
我的环境是PyTorch 2.5.1
Python 3.12(ubuntu22.04)
CUDA 12.4
ollama是一款轻便的部署框架,适合个人使用,优先是使用方便,缺点是功能简单,性能较差。
3.1 下载Ollama
进入以下官网,点击down,直接下载,有时下载很慢甚至连接失败,要多次尝试。
Ollama

使用以下命令
1
| curl -fsSL https://ollama.org.cn/install.sh | sh
|
3.2 运行ollama
安装完成后,需要启动ollama

可以看到,ollama服务的端口和IP为: 127.0.0.1:11434
所以启动前要保证这个端口不被占用。
服务开启后,该终端不能关闭,新开终端。输入命令
查看ollama保存的模型

可以看到,目前没有模型,到ollama官网搜索想要的模型
3.2.1 直接运行
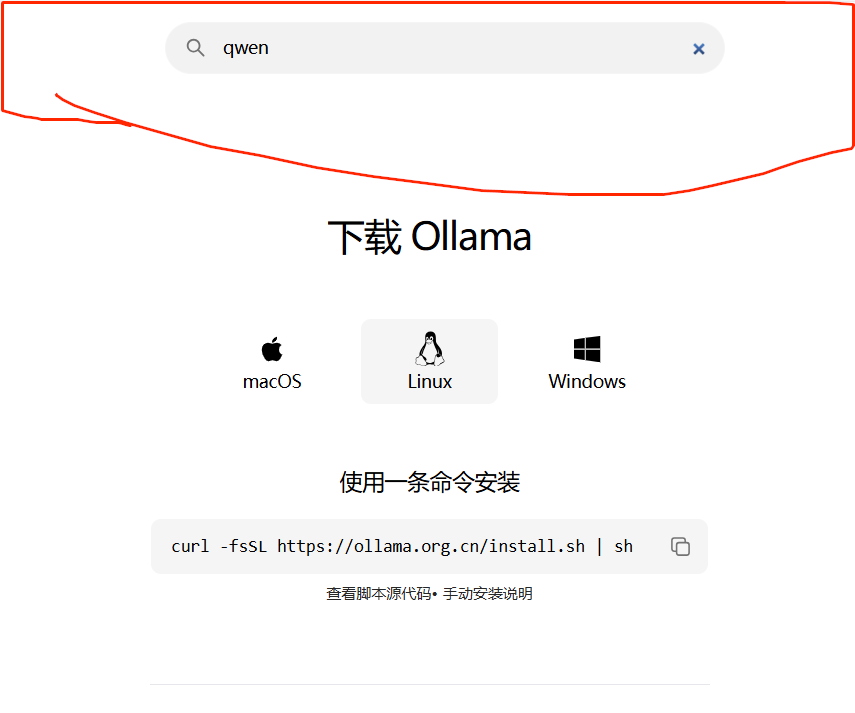
比如搜索Qwen2.5-0.5B,复制对应的指令
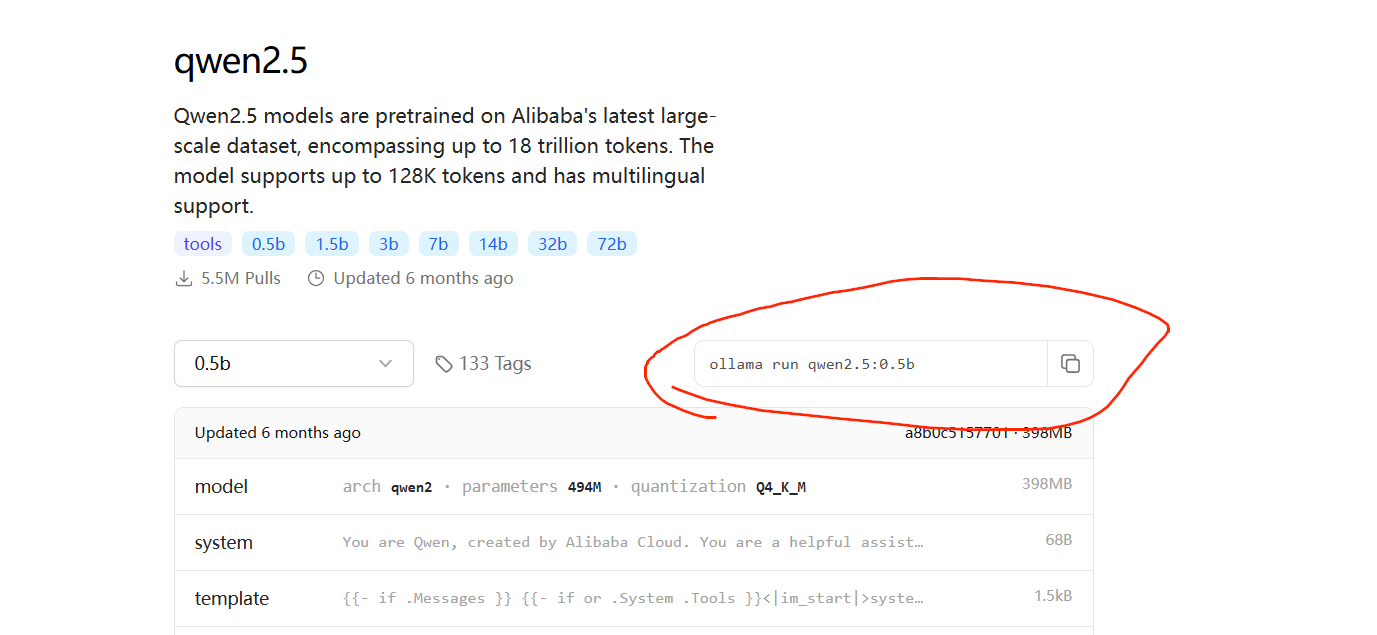
输入ollama run qwen2.5:0.5b 后会从ollama官网拉取模型并运行。

拉取后会直接运行,可以和大模型对话,输入/bye可以终止。输入
ollama list 查看模型,可以看到已经下载的模型

3.2.2 使用OpenAI的API风格调用
单论对话代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1/",
api_key="suibianxie",
)
completion = client.chat.completions.create(
model="qwen2.5:0.5b",
messages=[
{"role": "user", "content": "讲一个猫和老鼠的故事"}
]
)
print(completion.choices[0].message.content)
|
多轮对话代码如下, 单轮可以照着改。要注意model_name和ollama list 查到的模型名字一样,端口是上面ollama服务的端口和地址,这里是127.0.0.1:11434, api_key 随便写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
from openai import OpenAI
base_url = "http://localhost:11434/v1/"
api_key = "suibianxie"
model_name = "qwen2.5:0.5b"
def run_chat_session():
client = OpenAI(base_url=base_url,api_key=api_key)
chat_history = []
while True:
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
chat_history.append({"role":"user","content":user_input})
try:
chat_complition = client.chat.completions.create(messages=chat_history,model=model_name)
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
|
运行该文件后即可和大模型进行多轮对话

3.3 需要注意的问题
- Ollama目前只支持GGUF格式,和其他框架不同,所以如果我们要先从huggingface上下载模型,需要下载GGUF格式。
- GGUF格式是被量化后的模型,但是Ollama也能运行没量化的模型,具体方法后面补充。
四. vllm部署Qwen
4.1 安装vllm
官方文档:
快速入门 | vLLM 中文站
vllm只支持cuda12.4 和cuda11.8, 安装的时候如果cuda版本不符合会重新下载12.4的版本,所以要使用新的conda环境进行安装。
安装命令如下:
1
2
3
| conda create -n vllmEnv
conda activate vllmEnv
pip install vllm
|
4.2 开启vllm服务器
使用如下命令, 其中 ./Qwen2.5-0.5B-Instruct为模型命令,最好用绝对路径。
1
| vllm serve /mnt/workspace/Qwen2.5-0.5B-Instruct
|
开启成功后显示如下:
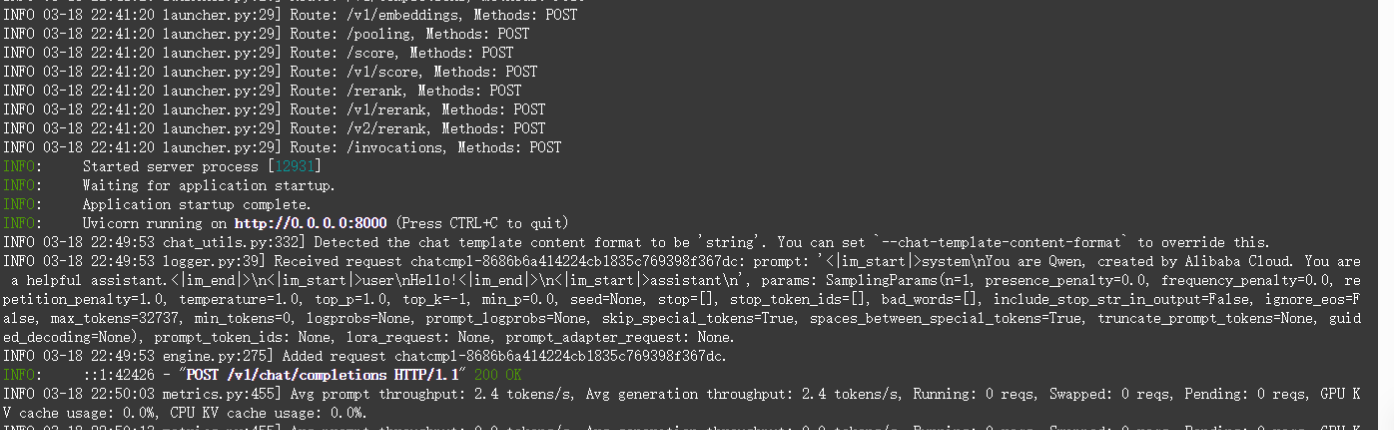
4.3 调用模型
vllm支持OpenAI格式调用,可以通过如下代码调用模型
注意:代码中api_key在实际引用中要和启动服务时的--api_key参数一致,在本地部署测试中可以随便写,但一定要有。另外,model和启动服务时指定的模型路径一致。
模型路径要用绝对路径,可以使用命令pwd查看当前根目录路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="/mnt/workspace/Qwen2.5-0.5B-Instruct",
messages=[
{"role": "user", "content": "讲一个猫和老鼠的故事"}
]
)
print(completion.choices[0].message.content)
|
服务器的终端不能关闭,重新开一个终端,运行上述代码。
运行后输出如下:

多轮对话是把每轮的输入输出加入到message中。示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
from openai import OpenAI
base_url = "http://localhost:8000/v1/"
api_key = "suibianxie"
model_name = "/mnt/workspace/Qwen2.5-0.5B-Instruct"
def run_chat_session():
client = OpenAI(base_url=base_url,api_key=api_key)
chat_history = []
while True:
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
chat_history.append({"role":"user","content":user_input})
try:
chat_complition = client.chat.completions.create(messages=chat_history,model=model_name)
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
|
运行结果如下图:
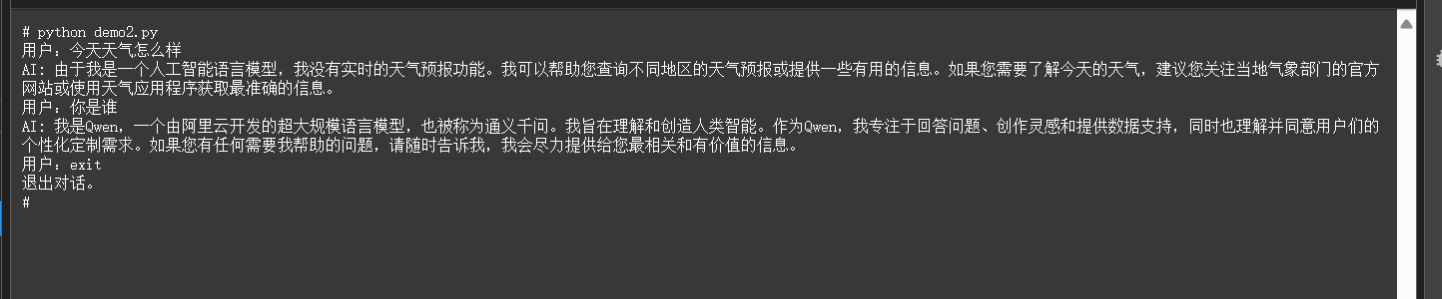
五. LMDeploy 部署Qwen
官网: 安装 — lmdeploy
5.1 安装LMDeploy
首先创建新的虚拟环境,我创建的版本是 LMDeploy支持的python版本是3.8-3.12, 支持的cuda是12+以上,11+也可以,我的版本是cuda12.4
1
2
3
| conda create -n lmdeploy python=3.8 -y
conda activate lmdeploy
pip install lmdeploy
|
从hf-mirror下载模型,比如我下载了qwen2.5-0.5B-Instruct,使用
5.2 启动服务
lmdeploy部署命令
1
| lmdeploy serve api_server /root/autodl-tmp/Qwen2.5-0.5B-Instruct --server-port 8000
|
启动成功: 注意,模型使用绝对路径,避免出错。

可以看到,模型部署在http://0.0.0.0:8000 上,使用openai接口可以直接访问,
5.3 调用模型
单轮对话代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="/root/autodl-tmp/Qwen2.5-0.5B-Instruct",
messages=[
{"role": "user", "content": "讲一个猫和老鼠的故事"}
]
)
print(completion.choices[0].message.content)
|
结果如下:

多轮对话代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
from openai import OpenAI
base_url = "http://localhost:8000/v1/"
api_key = "suibianxie"
model_name = "/root/autodl-tmp/Qwen2.5-0.5B-Instruct"
def run_chat_session():
client = OpenAI(base_url=base_url,api_key=api_key)
chat_history = []
while True:
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
chat_history.append({"role":"user","content":user_input})
try:
chat_complition = client.chat.completions.create(messages=chat_history,model=model_name)
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
|
运行结果如下:

六. 其他问题
6.1 移动anaconda位置
AutoDL 给的系统盘只有30G,数据盘有50G,如果安装太多环境,会导致系统跑满了,可以把Anaconda移动到数据盘。找到根目录下的miniconda文件夹,右键复制路径.
先把文件夹挪过去:
/root/miniconda3是原路径,/root/autodl-tmp/是移动目的目录,会自动再创建要给miniconda3目录
1
| mv /root/miniconda3 /root/autodl-tmp/miniconda3
|
然后创建软链接,相当于快捷方式
1
| ln -s /root/autodl-tmp/miniconda3 /root/miniconda3
|
6.2 查看当前目录绝对路径
