在二分类问题上微调Bert模型,介绍AI项目的开发流程,包括数据,模型,微调,评估,部署,以及介绍开发过程中细节,并给出各个步骤的代码。
一. 准备模型和数据
从huggingface上下载模型bert-base-chinese和数据集data/gpt2-chinese-cluecorpussmall (具体教程见上篇)
二. 分词器解读
使用transformers加载分词器, 打印分词器内容
1
2
3
4
| from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('./model/bert-base-chinese')
print(tokenizer)
|
运行后打印如下:
1
2
3
4
5
6
7
8
| BertTokenizer(name_or_path='./model/bert-base-chinese', vocab_size=21128, model_max_length=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True, added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
|
一些比较重要的参数如下:
vocab_size: 词典大小, 大模型没办法直接理解字符, 所以要先编码字符, 具体的编码方式是每个字符的编码是它在字符中的索引(从0开始),可以从模型文件夹中的vocab.json看到。词典中每个字有两个,比如白,一个是白, 一个是##白, 第一个是以字为单位,第二个是以词为单位(含上下文),所以词典包含的字符数其实是$\frac{vocab_size}{2}$ 目前大模型预训练一般以字为单位(训练难但扩展性好)。
special_toknes: 一些特殊符号,包括,不在词典中的字符用[UNK]代替。[PAD]用于填充,
比如句子“白日依山尽,” 可以从vocab.json中查到他们对应的索引,编码为[4635, 3189, 898, 2255, 2226, 8024](索引要从0开始), 使用如下代码测试(接上述代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
sents = ['白日依山尽,', '价格再找个地段属于适中,附近有早餐店,小饭店,比较方便,无早也无所']
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[sents[0], sents[1]],
add_special_tokens=True,
truncation=True,
max_length=9,
padding="max_length",
return_tensors=None,
return_attention_mask=True,
return_special_token = True,
return_special_tokens_mask= True,
return_length = True
)
for k, v in out.items():
print(f"{k} : {v}")
print(tokenizer.decode(out['input_ids'][0]))
print(tokenizer.decode(out['input_ids'][1]))
|
结果如下:

可以看出, 句子编码结果和推导一致,由于最大长度为9,所以第一个句子用[PAD]填充,第二个句子截断了。
input_ids: 编码结果
token_type_ids: 仅适用上下文编码, 第一个句子和特殊字符都是0, 第二个是1, 现在大多不适用了。
special_token_mask: 特殊字符的位置是1, 其他是0
length: 编码后的长度
三. Bert 增量微调:情感分析
3.0 AI项目开发流程
1
2
| graph LR
A[需求/数据]-->B[模型选型/设计]-->C[训练]-->D[效果评估]-->E[部署]
|
3.1 需求/数据
3.1.1 获取数据
使用如下代码从huggingface中下载数据集并保存到本地
1
2
3
4
5
| from datasets import load_dataset, load_from_disk
dataset = load_dataset(path='lansinuote/ChnSentiCorp')
dataset.save_to_disk(dataset_dict_path='./data/ChnSentiCorp')
|
保存后本地数据集结构如下:
使用如下代码从本地数据集加载
1
2
| dataset = load_from_disk('./data/ChnSentiCorp')
print(dataset)
|
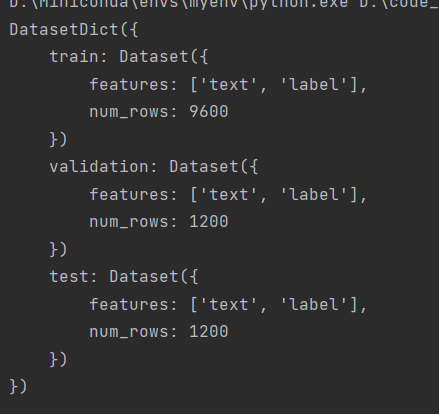
打印了数据集的结构:
扩展,一般我们自己的数据集是csv文件,也可以用load_dataset加载。也可以将数据集保存为csv文件.
3.1.2 转换数据格式
将数据转换为模型输入的数据格式。制作过程为定义自己的数据类,继承Dataset,重写三个函数,模板如下:
1
2
3
4
5
6
7
8
9
10
11
| from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
pass
def __len__(self):
pass
def __getitem__(self, item):
pass
|
在本项目中, 定义MyDataset类如下,存放在MyData.py文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
def __init__(self, split):
self.dataset = load_from_disk('./data/ChnSentiCorp')
if split == "train":
self.dataset = self.dataset['train']
elif split == 'test':
self.dataset = self.dataset['test']
elif split == 'validation':
self.dataset = self.dataset['validation']
else:
print("数据集中没有该结构")
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
text = self.dataset[item]['text']
label = self.dataset[item]['label']
return text, label
if __name__ == "__main__":
dataset = MyDataset("test")
for data in dataset:
print(data)
|
运行后打印测试集:

3.2 模型设计
使用增量微调, 即模型分为两个部分,先用Bert生成词嵌入,再在后面接上我们的分类模型,在训练时,冻结嵌入模型Bert,只训练分类模型。
定义自己的模型类,存放在net.py文件中:
通过打印模型结构,可以看到Bert模型最后将一个句子嵌入为768维的向量,所以我们增量模型的输入为768维的向量,输出为2维向量(二分类任务)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import torch
from transformers import BertModel
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
pretrained = BertModel.from_pretrained("./model/bert-base-chinese").to(DEVICE)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
with torch.no_grad():
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
out = self.fc(out.last_hidden_state[:,0])
return out
|
为什么用增量微调: 数据量少,没办法训练整个模型,设备差,增量微调训练起来快。
3.3 模型训练
定义tain.py文件,分为几个步骤,加载数据集,加载模型,训练和监控。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer, AdamW
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained('./model/bert-base-chinese')
EPOCH = 3000
def collate_fn(data):
sents = [i[0] for i in data]
label = [i[1] for i in data]
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
max_length=512,
padding="max_length",
return_tensors="pt",
return_length=True
)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
label = torch.LongTensor(label)
return input_ids, attention_mask, token_type_ids, label
train_dataset = MyDataset('train')
train_loader = DataLoader(
dataset=train_dataset,
batch_size=20,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
if __name__ == "__main__":
model = Model().to(DEVICE)
optimizer = AdamW(model.parameters())
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for i, (input_ids, attention_mask, token_type_ids, label) in enumerate(train_loader):
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE), attention_mask.to(DEVICE), token_type_ids.to(DEVICE), label.to(DEVICE)
out = model(input_ids, attention_mask, token_type_ids)
loss = loss_func(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 5 == 0:
out = out.argmax(dim=1)
acc = (out==label).sum().item()/len(label)
print(f"epoch:{epoch}, i{i}, loss:{loss.item()}, acc:{acc}")
torch.save(model.state_dict(), f"./params/{epoch}_bert.pth")
print("参数保存成功")
|
运行后结果如下:

3.4 模型评估
模型评估分为两种:客观评估和主观评估,客观评估是指在测试集上验证指标,比如在这个二分类任务中,指标可以用准确率。
3.4.1 客观评估
客观评估主要步骤为
1
2
3
| graph LR
A[加载测试集]-->B[加载模型]-->C[获得输出]-->D[计算指标]
|
注意:推理时候需要开启模型的推理模式,使用以下语句
主要影响模型的Batch Normalization层和Droupout层,当开启推理模式时,这两个层会有不同的行为:
Batch Normalization层: 使用全局均值和方差,而不是当前batch的均值和方差。Droupout层:不会随机丢弃神经元
同时,在推理的时候不需要后向传播,所以可以不计算梯度,从而节约显存,加速推理, 使用以下语句:
1
2
3
4
|
with torch.no_grad():
out = model(input_ids, attention_mask, token_type_ids)
|
测试的具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained('./model/bert-base-chinese')
def collate_fn(data):
sents = [i[0] for i in data]
label = [i[1] for i in data]
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
max_length=512,
padding="max_length",
return_tensors="pt",
return_length=True
)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
label = torch.LongTensor(label)
return input_ids, attention_mask, token_type_ids, label
test_dataset = MyDataset('test')
test_loader = DataLoader(
dataset=test_dataset,
batch_size=20,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
if __name__ == "__main__":
model = Model().to(DEVICE)
model.load_state_dict(torch.load("./params/7_bert.pth"))
model.eval()
acc = 0.0
for i, (input_ids, attention_mask, token_type_ids, label) in enumerate(test_loader):
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE), attention_mask.to(
DEVICE), token_type_ids.to(DEVICE), label.to(DEVICE)
with torch.no_grad():
out = model(input_ids, attention_mask, token_type_ids)
out = out.argmax(dim=1)
acc += (out == label).sum().item()
print(i, (out == label).sum().item())
print(f"准确率为{acc/len(test_loader)}")
|
3.4.2 主观评估
主观评估就是让用户输出字符串,然后直接判断该字符串的标签。具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained('./model/bert-base-chinese')
model = Model().to(DEVICE)
names = ["负向评价","正向评价"]
def collate_fn(data):
sents = [data]
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents,
truncation=True,
max_length=512,
padding="max_length",
return_tensors="pt",
return_length=True
)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
return input_ids, attention_mask, token_type_ids
if __name__ == '__main__':
model.load_state_dict(torch.load("params/7_bert.pth"))
model.eval()
while True:
data = input("请输入测试数据(输入q退出):")
if data == 'q':
print("测试结束")
break
input_ids, attention_mask, token_type_ids = collate_fn(data)
input_ids, attention_mask, token_type_ids = input_ids.to(DEVICE), attention_mask.to(DEVICE), token_type_ids.to(
DEVICE)
with torch.no_grad():
out = model(input_ids, attention_mask, token_type_ids)
out = out.argmax(dim=1)
print(f"模型判定结果为: {names[out]}")
|
四. 扩展到其他多分类任务上
如果想扩展到多分类任务上,比如扩展到8分类任务上, 只需修改一些地方,比如修改模型的全连接层,在二分类时,我们的增量模型是一个输出为二维的向量,8分类时只需要改为输出为八维。修改net.py为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import torch
from transformers import BertModel
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
pretrained = BertModel.from_pretrained("./model/bert-base-chinese").to(DEVICE)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768, 8)
def forward(self, input_ids, attention_mask, token_type_ids):
with torch.no_grad():
out = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
out = self.fc(out.last_hidden_state[:,0])
return out
|
另外还需要修改数据类,MyData.py, 具体修改可以根绝数据集格式更改。
其他不用改变,可以直接训练或者测试。
五. 补充
4.1 训练的状态
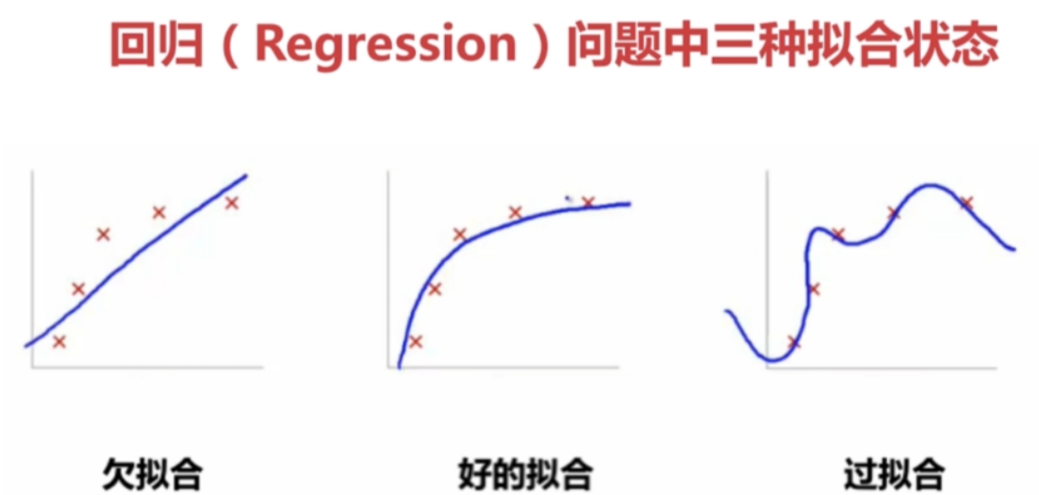
Ai模型在训练过程中存在三种状态:
- 欠拟合:模型的分布弱于数据真实分布(可能的原因:训练时间不够,模型过于简单)
- 拟合:模型的分布恰好能够表达数据的核心分布规律(训练的理想状态)
- 过拟合:模型过度拟合数据的分布规律,会使得模型的结果依赖于数据中的噪声信息,一旦数据发生细微变化,就可能会导致结果错误。
如下图:
处理方法:
- 欠拟合:继续训练
- 过拟合:无法返回,通过在训练过程中不断保存checkpoints,出现过拟合时找到拟合点,即为最佳拟合点。
最佳拟合点判断, 使用验证集,在训练过程中同时测试在验证集上的loss,当发现模型在训练集上loss仍在下降,但在验证集上loss上升时,说明模型出现过拟合。
4.2 Batch Normaliztion(BN)的原理和作用
在深度神经网络中,随着 层数加深,神经元的输入分布可能会发生变化(即 内部协变量偏移,Internal Covariate Shift)。这会导致:
✅ 梯度消失或梯度爆炸,训练变得不稳定。
✅ 模型收敛速度慢,需要更小的学习率。
✅ 对初始化敏感,不同的权重初始化可能导致不同的训练结果。
Batch Normalization 通过归一化(Normalization)和可训练参数(Scaling & Shifting)来解决这些问题。
Batch Normalization 的作用:
✅ (1) 让训练更稳定
- 归一化可以防止 梯度消失/梯度爆炸,使得训练更加稳定。
✅ (2) 提高收敛速度
- BN 让数据分布更稳定,可以使用 更大的学习率(learning rate),加速训练。
✅ (3) 降低对权重初始化的依赖
- 由于 BN 让数据保持稳定分布,网络在不同初始化下表现更一致。
✅ (4) 具有一定的正则化效果
- 由于 BN 依赖于 batch 统计信息,训练时会引入一定的噪声,类似 Dropout,能减少过拟合。
